Recherche dichotomique (Bac 🎯)⚓︎

Ce cours est mis à disposition selon les termes de la Licence Creative Commons Attribution - Pas d'Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 International.
Sources et crédits pour ce cours
Pour préparer ce cours, j'ai utilisé :
- le manuel NSI chez Ellipses de Balabonski, Conchon, Filliâtre, Nguyen
- le cours de mon collègue Pierre Duclosson
- la ressource Eduscol sur la méthode Diviser pour régner.
🔖 Synthèse de ce qu'il faut retenir pour le bac
Retour sur la recherche dichotomique⚓︎
Algorithme 1 : recherche dichotomique dans un tableau trié
Spécification du problème :
- On dispose d'un tableau
tabd'éléments de même type et compararables. De plus le tableau est trié dans l'ordre croissant et les indices commencent à \(0\). - On nous donne un élément
edu même type que ceux du tableau. - On veut rechercher une occurrence de
edans le tableau et renvoyer son indice. Sien'est pas dans le tableau, on renverra \(-1\).
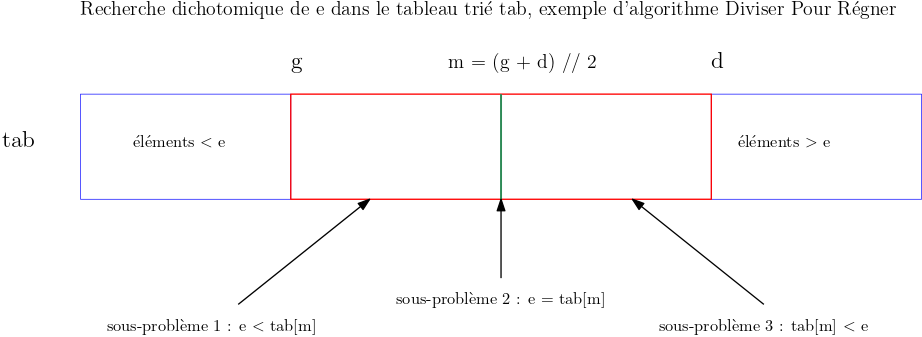
L'algorithme de recherche dichotomique exploite l'ordre sur les éléments pour diviser au moins par deux la taille de la zone de recherche à chaque étape. On note g et d les indices délimitant à gauche et à droite la zone de recherche. On initialise g avec \(0\) et d avec la longueur du tableau moins 1. Ensuite on répète les étapes suivantes jusqu'à ce que l'on trouve une occurrence de e ou que la zone de recherche soit vide (cas où e n'est pas dans le tableau).
- Diviser : On calcule l'indice du milieu de la zone de recherche
m = (g + d) // 2et on se ramène à la résolution de trois sous-problèmes plus petits et similaires :
Attention
Puisque g, d et m sont des indices dans un tableau, ils doivent être de type int donc il faut impérativement utiliser la division euclidienne // pour que m = (g + d) // 2 soit un entier. Sinon en Python, on aura une erreur :
>>> t = [-4, 8, 19]
>>> g, d = 0, 2
>>> m = (g + d) / 2
>>> t[m]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: list indices must be integers or slices, not float
-
Résoudre : On résout directement le sous-problème 1 si
tab[m] = eet sinon on résout récursivement l'un des deux autres sous-problèmes :- Si
e < tab[m], sous-problème 2 : l'élémentene peut être que dans la première moitié de la zone de recherche correspondant aux indices dans l'intervalle[g, m[ - Si
tab[m] < e, sous-problème 3 : l'élémentene peut être que dans la seconde moitié de la zone de recherche correspondant aux indices dans l'intervalle]m, d]
- Si
Voir aussi le mémo spécial Dichotomie.
Exercice 1
Question 1
Exécutez pas à pas l'algorithme de recherche dichotomique pour chercher la valeur \(9\) dans le tableau trié [-4, 0, 1, 5, 9, 17, 42, 100].
Recopiez et complétez le tableau suivant avec les valeurs des variables g, d et m prises après l'étape Diviser et avant l'étape Résoudre :
g |
d |
m |
|---|---|---|
| 0 | 7 | 3 |
| ... | ... | ... |
| ... | ... | ... |
g |
d |
m |
|---|---|---|
| 0 | 7 | 3 |
| 3 | 7 | 5 |
| 3 | 5 | 4 |
On trouve finalement une occurrence de l'élément 9 à l'indice 4.
Question 2
Rechercher dans un tableau de \(386265\) mots de la langue française, le mot dichotomie avec l'outil de visualisation de Frédéric Boissac : http://fred.boissac.free.fr/AnimsJS/Dariush_Dichotomie/index.html.
- Quelle propriété du tableau permet d'effectuer une recherche dichotomique ?
- Combien de comparaisons sont nécessaires ?
- Combien de comparaisons auraient été nécessaires avec une recherche séquentielle ?
- Une recherche dichotomique dans ce tableau de mots est possible car il est trié dans l'ordre croissant.
- Il faut \(16\) comparaisons pour trouver dichotomie. Il en faudrait au maximum \(19\) pour trouver un mot dans le tableau trié de \(386265\) mots car \(2^{18} < 386265 < 2^{19}\).
- Avec une recherche séquentielle, puisque dichotomie est en position \(125795\) il aurait fallu \(125795\) comparaisons.

Question 3
💻 Saisir ses réponses sur Capytale
Complétez la fonction recherche_dicho_iter pour donner une implémentation itérative de l'algorithme de recherche dichotomique dans un tableau trié.
def recherche_dicho_iter(t, e):
"""
Recherche dichotomique dans un tableau trié dans l'ordre croissant
Algorithme itératif avec une boucle
Paramètres :
t : tableau d'éléments de même type et comparables
précondition : t trié dans l'ordre croissant
e : un élément du même type que ceux dans tab
Retour:
Si e dans tab renvoie l'index d'une occurrence
Sinon renvoie -1
"""
g, d = 0, len(t) - 1
while g <= d:
m = (g + d) // 2
# Sous-problème 1 : occurrence de e en t[m]
if e == t[m]:
return m
# Sous-problème 2 :
# on continue la recherche dans la première moitié [g, m [ = [g, m - 1]
elif e < t[m]:
d = m - 1
# Sous problème 3
# on continue la recherche dans la seconde moitié [m + 1, d]
else:
g = m + 1
return -1
Question 4
💻 Saisir ses réponses sur Capytale
Complétez la fonction recherche_dicho_rec dans l'éditeur précédent, pour donner une implémentation récursive de l'algorithme de recherche dichotomique dans un tableau trié.
recherche_dicho_rec va prendre quatre paramètres : le tableau t, l'élément cherché e, la limite gauche de la zone de recherche g et la limite droite de la zone de recherche d.
On peut écrire une fonction recherche_dicho_rec_env avec juste deux paramètres t et e comme recherche_dicho_iter. Il suffit qu'elle renvoie la valeur de recherche_dicho_rec appelée avec les bons arguments.
def recherche_dicho_rec(t, e, g, d):
"""
Recherche dichotomique dans un tableau trié dans l'ordre croissant
Algorithme récursif
Paramètres :
t : tableau d'éléments de même type et comparables
précondition : t trié dans l'ordre croissant
e : un élément du même type que ceux dans tab
g : index limite à gauche de la zone de recherche
d : index limite à droite de la zone de recherche
Retour:
Si e dans tab renvoie l'index d'une occurrence
Sinon renvoie -1
"""
m = (g + d) // 2
# 1er cas de base : zone de recherche vide
if g > d:
return -1
# Sous-problème 1
# 2eme cas de base : occurrence de e en t[m]
if t[m] == e:
return m
# Sous problème 2
# on continue la recherche dans la première moitié [g, m [ = [g, m - 1]
elif e < t[m]:
return recherche_dicho_rec(t, e, g, m - 1)
# Sous problème 3
# on continue la recherche dans la seconde moitié [m + 1, d]
else:
return recherche_dicho_rec(t, e, m + 1, d)
def recherche_dicho_rec_env(t, e):
"""Fonction enveloppe pour la recherche dichotomique récursive
de l'élément e dans le tableau.
Masque le passage des arguments représentant les limites de la zone
de recherche
"""
return recherche_dicho_rec(t, e, 0, len(t) - 1)
Exercice 2
Question 1 : terminaison
En vous appuyant sur la version itérative de la recherche dichotomique d'un élément dans un tableau trié, et d'un variant de boucle démontrez la terminaison de cet algorithme.
Recherche dichotomique itérative
def recherche_dicho_iter(t, e):
g, d = 0, len(t) - 1
while g <= d:
m = (g + d) // 2
if e == t[m]:
return m
elif e < t[m]:
d = m - 1
else:
g = m + 1
return -1
La fonction contient deux return :
- si le
return mdans la boucle est exécuté, l'algorithme se termine. - sinon,
return mn'est jamais exécuté et l'algorithme se termine si et seulement si la bouclewhilese termine.
Démontrons que la valeur de d - g est un variant pour la boucle while
- (P1) :
d - gest un entier avant la boucle - (P2) : une itération de boucle s'exécute uniquement si
g <= dc'est-à-dired - g >= 0 - (P3) : Supposons que
d - gsoit un entier positif avant une exécution d'une itération complète de la boucle. Puisqu'on est dans le cas oùreturn mne s'exécute pas, en sortie de boucle on est dans l'un des deux cas suivants : soit la valeurga augmenté de 1, soit la valeur deda dminué de 1. Dans les deux cas, la valeur ded - ga diminué de 1 donc est strictement inférieure à sa valeur en entrée de boucle. De plusd - greste un entier.
Les trois propriétés (P1), (P2) et (P3) sont vérifiées donc la valeur de d - g est un variant pour la boucle while. Ceci prouve la terminaison de l'algorithme.
Question 2 : correction
En vous appuyant sur la version itérative de la recherche dichotomique d'un élément dans un tableau trié, et d'un invariant de boucle démontrez la correction de cet algorithme.
La fonction contient deux return, donc il faut considérer deux cas :
- 1er cas : si le
return mest exécuté, cela doit correspondre à une position deedanst, c'est vrai puisque cette instruction est exécutée sit[m] == e. - 2eme cas : si le
return -1est exécuté, cela doit correspondre au cas oùen'est pas dans le tableau. On va le démontrer.
Démontrons alors que la propriété suivante \(\mathcal{P}\) suivante est un invariant de la boucle while.
\(\mathcal{P}\) := "Tous les éléments du tableau
td'indicei < gsont strictement inférieurs à l'élémenteet tous les éléments du tableautd'indicej > dsont strictement supérieurs à l'élémente"
- (Initialisation) : Avant la boucle, on a
g = 0etd = len(t) - 1donc il n'existe aucun élément detd'indice \(i<g\) ou d'indice \(j>d\), donc \(\mathcal{P}\) est vraie. - (Préservation) : Supposons que \(\mathcal{P}\) soit vraie avant une itération qui s'exécute complètement. On est dans le cas où
return mne s'exécute pas. Sie < t[m], alors tous les éléments detd'indicej >= mvérifiente < t[m] <= t[j]cartest dans l'ordre croissant. En choisissantd = m - 1, on préserve donc la propriété \(\mathcal{P}\). Symétriquement, la propriété sera préservée sie > t[m].
La propriété \(\mathcal{P}\) est donc un invariant de la boucle while. On a déjà prouvé que l'algorithme se termine. En sortie de boucle, elle est encore vraie : les seuls éléments de t qui peuvent être égaux à e ont donc un indice \(\geqslant g\) et \(\leqslant d\). Mais en sortie de boucle, on a \(g > d\) donc cet ensemble est vide. On en déduit qu'il n'existe pas d'éléments de t égaux à e et donc il est correct d'exécuter return -1.
Question 3: complexité
Pour un tableau de taille \(n\) quel nombre maximum de comparaisons doit-on effectuer dans le cas où l'élément e recherché ne se trouve pas dans le tableau tab ?
Soit \(k\) le plus petit entier tel que \(n < 2^{k}\).
Après chaque comparaison de e avec tab[m], on divise la zone de recherche au moins par 2 puisque m = (g + d) // 2. Ainsi la taille \(t(i)\) de la zone de recherche vérifie la récurrence :
- \(t(0)= n\)
- \(t(i+1) \leqslant \frac{1}{2} \times t_{i}\)
Avec un raisonnement par récurrence on démontre que \(t(i) \leqslant \frac{n}{2^{i}}\).
Si e n'est pas dans tab, l'algorithme se termine si et seulement si la zone de recherche est vide.
Or sa taille est un entier, donc l'algorithme se termine si et seulement si \(t(i) < 1\).
Dans le pire des cas, puisque \(t(i) \leqslant \frac{n}{2^{i}}\), on aura \(t(i) < 1\) dès que \(\frac{n}{2^{i}} < 1 \Longleftrightarrow n < 2^{i}\).
\(i\) est un entier donc le nombre maximal de comparaisons est le plus petit entier naturel \(i\) tel que \(n < 2^{i}\), c'est-à-dire \(\lceil \log_{2}(n) \rceil\), c'est exactement le nombre de chiffres en base \(2\) de \(n\).
L'algorithme de recherche dichotomique dans un tableau trié est donc de complexité logarithmique, en \(O(\log_{2}(n))\). Le nombre de chiffre en base 2 est très inférieur à sa valeur, d'autant plus si le nombre est grand, la complexité logarithmique de la recherche dichotomique est donc bien meilleure que la complexité linéaire d'une recherche séquentielle, mais il faut que le tableau soit trié !
Méthode Diviser pour Régner⚓︎
Point de cours 1
La méthode Diviser Pour Régner 1 est une généralisation de la dichotomie.
Un algorithme de type Diviser pour Régner est caractérisé par trois étapes :
- Diviser : étant donné le problème à résoudre, on découpe l'entrée en deux ou plusieurs sous-problèmes similaires, plus petits et indépendants.
- Résoudre : on résout tous les sous-problèmes :
- soit directement si la solution est simple (cas de base)
- soit en appelant l'algorithme sur le sous-problème (appel récursif)
- Combiner : à partir des solutions des sous-problèmes on reconstitue une solution du problème initial 2.
La réduction d'un problème à des sous-problèmes similaires et plus petits, conduit naturellement à une programmation récursive.
Remarque
Dans le cas de la recherche d'un élément dans un tableau trié, la méthode Diviser pour Régner permet d'améliorer la complexité par rapport à un autre type d'algorithme, mais on verra sur d'autres problèmes que ce n'est pas toujours le cas.
| Algorithme de recherche dans un tableau trié | Complexité dans le pire des cas |
|---|---|
| Recherche dichotomique (Diviser pour Régner) | logarithmique \(O(\log_{2}(n))\) |
| Recherche séquentielle | linéaire \(O(n)\) |
Exercice 3
Problème (P)
On considère le problème suivant : rechercher le maximum d'un tableau d'entiers tab de taille n.
En classe de première, vous avez résolu ce problème avec un algorithme de recherche séquentielle, dont voici une implémentation :
def maximum_tab(tab):
assert len(tab) > 0, "tableau vide"
maxi = tab[0]
for elt in tab:
if elt > maxi:
maxi = elt
return maxi
Question 1
Quelle est la complexité de cet algorithme de recherche séquentielle en fonction de la taille \(n\) du tableau ?
Tous les éléments du tableau doivent être comparés exactement une fois au maximum provisoire, donc la complexité de cet algorithme est linéaire, en \(O(n)\).
Question 2
💻 Saisir ses réponses sur Capytale
Si on divise le tableau en deux au niveau de l'indice m = len(tab) // 2, on peut découper le problème en deux sous-problèmes :
- sous-problème 1 : rechercher le maximum de la première moitié du tableau
tab[:m]. - sous-problème 2 : rechercher le maximum de la seconde moitié du tableau
tab[m:].
À partir de ce découpage, écrivez, en Python, un algorithme de type Diviser pour Régner qui répond au problème de recherche du maximum dans un tableau d'entiers. Vous nommerez cette fonction maximum_dpr.
Indiquez par des commentaires les différentes étapes, Diviser, Résoudre et Combiner.
À partir du découpage proposé, on peut écrire une fonction récursive qui résout le problème avec la méthode Diviser pour Régner.
def maximum_dpr(tab):
"""
Renvoie le maximum d'un tableau d'entiers
Algorithme récursif avec méthode Diviser pour Régner
"""
# Cas de base des appels récursifs : sous-problème de résolution directe
if len(tab) == 1:
return tab[0]
# Division en sous-problèmes :
# on divise en deux sous-tableaux : première et deuxième moitié
m = len(tab) // 2
# Résoudre les deux sous-problèmes par des appels récursifs
m1 = maximum_dpr(tab[:m])
m2 = maximum_dpr(tab[m:])
# Combiner les solutions des deux sous-problèmes
# on prend le maximum des solutions des deux solutions des sous-problèmes
if m1 >= m2:
return m1
return m2
Question 3
💻 Saisir ses réponses sur Capytale
Complétez le code de la fonction maximum_dpr avec la solution de la question précédente, puis exécutez test_double_ratio(2 ** 7). Des appels de la fonction maximum_dpr sont exécutés sur des entrées dont la taille double à chaque nouvel essai : chaque ratio entre le temps d'un essai et celui du précédent est affiché.
Quelle conjecture peut-on faire sur la complexité de la fonction maximum_dpr par rapport à la taille \(n\) du tableau en entrée ?
On peut observer que le temps d'exécution de maximum_dpr double lorsque la taille de l'entrée double. On peut donc conjecturer que la complexité de cet algorithme est linéaire, en \(O(n)\).
Question 4
Vous allez démontrer la conjecture sur la complexité de l'algorithme Diviser pour Régner implémenté par maximum_dpr dans le cas simplifié d'un tableau d'entrée de taille \(n=2^{k}\).
On note \(t(2^{k})\) le temps d'exécution pour une entrée de taille \(2^{k}\).
- Justifiez qu'on peut écrire la relation de récurrence \(t(2^{k})=2 \times t(2^{k-1})\).
- En déduire une expression de \(t(2^{k})\) en fonction de \(k\) puis la complexité de l'algorithme Diviser pour Régner dans ce cas.
- La méthode Diviser pour Régner permet-elle d'améliorer la complexité dans ce cas ?
On a :
Temps(Total) = Temps(Diviser) + Temps(Résoudre) + Temps(Combiner)
Avec les notations choisies, sachant qu'on a deux sous-problèmes de taille \(n/2 = 2^{k} / 2 = 2^{k - 1}\), il vient :
\(t(2^{k}) =\) Temps(Diviser) + \(2 \times t(2^{k-1})\) + Temps(Combiner)
On peut considèrer que l'étape Diviser est de coût constant. Ce n'est pas vrai en Python avec les découpages en tranche tab[:m] et tab[m:]. Mais on pourrait travailler à coût constant, en délimitant chaque tranche par des indices.
L'étape Combiner consiste à comparer deux entiers donc on peut considérer qu'elle s'exécute aussi en temps constant.
Finalement, en négligeant ls temps constants, on peut écrire :
\(t(2^{k}) = 2 \times t(2^{k-1})\)
Notons \(u_{k}\) la suite de terme général \(t(2^{k})\), la relation de récurrence précédente se traduit par \(u_{k} = 2 \times u_{k-1}\). On reconnaît une suite géométrique de raison \(2\), donc on a \(u_{k} = C \times 2^{k}\) avec \(C\) constante. Ainsi on a \(t(2^{k})= C \times 2^{k}\). Or on avait posé \(n=2^{k}\), donc on a \(t(n)=C \times n\).
Ceci prouve que dans le cas particulier où \(n=2^{k}\), la complexité de l'algorithme Diviser pour Régner est donc linéaire comme celle de la recherche séquentielle.
Cette fois la méthode Diviser pour Régner ne permet pas d'améliorer la complexité comme pour la recherche dichotomique dans un tableau trié par rapport à une recherche séquentielle.