Algorithmes de référence 🎯
Les algorithmes marqués d'un  sont à connaître sur le bout des doigts, les autres sont des classiques qu'il est bon d'avoir rencontré au moins une fois.
sont à connaître sur le bout des doigts, les autres sont des classiques qu'il est bon d'avoir rencontré au moins une fois.
Tableaux dynamiques / listes Python⚓︎
Tous ces algorithmes prennet en entrée un tableau de \(n\) éléments de même type. On note \(C(n)\) le coût en opérations élémentaires de l'algorithme. Une opération est élémentaire si elle est de coût constant (comparaison de deux valeurs d'un des types de base, affectation etc ...)
Complexité logarithmique⚓︎
Définition
Une complexité logarithmique dans le pire des cas signifie qu'il existe une constante \(k\) telle que : \(C(n) \leqslant k \log(n)\). Il est équivalent de dire que le coût \(C(n)\) de l'algorithme est majoré par le produit d'une constante fois le nombre de chiffres de \(n\) (cela ne dépend pas de la base choisie).
C'est une complexité excellente !
Recherche dichotomique
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Tableau d'entiers | Trié dans l'ordre croissant | Entier | Renvoie l'indice d'une occurrence de elt dans tab ou \(-1\) sinon |
| Taille de l'entrée | Complexité dans le pire des cas |
|---|---|
| tableau de \(n\) éléments | logarithmique en \(O(\log(n))\) |
Voir le mémo spécial Dichotomie.
def recherche_dicho(tab, elt):
g = 0
d = len(tab) - 1
while g <= d:
# Invariant : tab[k] < elt si k < g et t[k] > elt si k > d
m = (g + d) // 2
if tab[m] < elt:
g = m + 1
elif tab[m] > elt:
d = m - 1
else:
return m
return -1
def dicho_rec(tab, elt, g, d):
if g > d: # cas de base : zone de recherche vide
return -1
m = (g + d) // 2
if tab[m] == elt: # cas de base : élément trouvé
return m
elif tab[m] < elt:
return dicho_rec(tab, elt, m + 1, d)
else: # sous-problème 2 tab[m] > elt:
return dicho_rec(tab, elt, g, m - 1)
def recherche_dicho(tab, elt):
return dicho_rec(tab, elt, 0, len(tab) - 1)
Complexité linéaire⚓︎
Définition
Une complexité linéaire dans le pire des cas signifie qu'il existe une constante \(k\) telle que : \(C(n) \leqslant k n\). Il est équivalent de dire que le coût \(C(n)\) de l'algorithme est majoré par le coût de la lecture de son entrée (à une constante près).
C'est une très bonne complexité !
Recherche linéaire
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Tableau | Non vide | Booléen | Détermine si elt appartient au tableau tab |
| Taille de l'entrée | Complexité dans le pire des cas |
|---|---|
| tableau de \(n\) éléments | linéaire en \(O(n)\) |
def recherche(tab, elt):
for e in tab:
if e == elt:
return True
return False
Recherche de maximum
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Tableau | Non vide | Type d'élément de tableau | Renvoie la valeur maximale du tableau tab |
| Taille de l'entrée | Complexité dans le pire des cas |
|---|---|
| tableau de \(n\) éléments | linéaire \(O(n)\) |
def maximum(tab):
m = tab[0]
for e in tab: # parcours par valeur
if e > m:
m = e
return m
Positions du maximum
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Tableau | Non vide | Tableau | Renvoie la listes des positions du maximum de tab |
| Taille de l'entrée | Complexité dans le pire des cas |
|---|---|
| tableau de \(n\) éléments | linéaire en \(O(n)\) |
def pos_maximum(tab):
lis = [0]
m = tab[0]
for k in range(len(tab)): # parcours par index
if tab[k] > m:
m = tab[k]
lis = [k]
elif tab[k] == m:
lis.append(k)
return lis
Conversion en base 2 d'un entier donné en base dix
| Entrée | Sortie | Spécification |
|---|---|---|
| Entier | Tableau | Renvoie le tableau des chiffres d'un entier en base 2, par bit de poids croissant de gauche à droite |
| Taille de l'entrée | Complexité dans le pire des cas |
|---|---|
| Nombre de chiffres de l'entier \(n\) (peu importe la base) soit \(p=\log(n)\) | le nombre de chiffres de \(n\) soit \(O(\log(n))=O(p)\), donc du même ordre de grandeur que l'entrée, donc linéaire |
Attention
L'ordre de grandeur \(O(\log(n))\) peut nous inciter à classer naïvement cet algorithme parmi ceux de complexité logarithmique. Cependant l'ordre de grandeur de la taille de l'entrée n'est pas \(n\) mais le nombre de bits pour stocker l'entier en mémoire donc \(\log(n)\) à une constante près. Dans un ordinateur, la base de représentation choisie est la base 2 mais les nombres de chiffres dans deux bases distinctes sont proportionnels donc la taille de l'entrée ne dépend pas de la base et le coût de l'algorithme en opérations élémentaires, en \(O(\log(n))=O(p)\) est bien du même ordre de grandeur que celui de l'entrée \(p= \log(n)\), ce qui caractérise une complexité linéaire.
On collecte d'abord les bits de poids faibles, donc il faut renverser la liste de bits quand elle est complète.
def decimal_vers_binaire(n):
bits = []
while n >= 2:
bits.append(n % 2)
n = n // 2
bits.append(n)
bits.reverse()
return bits
On collecte un bit de poids plus faible dans la fonction que dans l'appel récursif mais en l'ajoutant à la fin de la liste renvoyée par l'appel récursif, il est à sa place.
def decimal_vers_binaire_rec(n):
if n < 2:
return [n]
rep = decimal_vers_binaire_rec(n // 2)
rep.append(n % 2)
return rep
Rendu de monnaie glouton
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Somme à rendre et tableau des valeurs des pièces disponibles | Aucune | Tableau | Renvoie le tableau des pièces dont la somme égale celle qu'il faut rendre |
La complexité dépend de la somme à rendre et des pièces disponibles, en particulier de la valeur minimale de pièce. Dans le pire ces cas, le nombre d'opérations sera majoré par le quotient de la somme à rendre par la valeur minimale de pièce.
⚠️ on suppose que le rendu exact est possible avec les valeurs des pièces disponibles et qu'on dispose d'un nombre infini de pièces de chaque valeur.
def rendu_glouton(restant, pieces):
# pieces tableau de valeurs de pièces disponibles dans l'ordre croissant
indice_pieces = len(pieces) - 1
rendu = []
while restant > 0 and indice_pieces >= 0:
if pieces[indice_pieces] <= restant:
restant = restant - pieces[indice_pieces]
rendu.append(pieces[indice_pieces])
else:
indice_pieces = indice_pieces - 1
# rendu possible
return rendu
def rendu_rec(restant, pieces, indice_pieces):
# pieces contient les valeurs des pièces disponibles par ordre croissant
if restant == 0:
return []
if pieces[indice_pieces] <= restant:
rep = rendu_rec(restant - pieces[indice_pieces], pieces, indice_pieces)
rep.append(pieces[indice_pieces])
else:
rep = rendu_rec(restant, pieces, indice_pieces - 1)
return rep
def rendu_glouton(restant, pieces):
return rendu_rec(restant, pieces, len(pieces) - 1)
Fusion de deux tableaux triés dans l'ordre croissant
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Deux tableaux | Triés dans l'ordre croissant | Tableau | Fusionne les deux tableaux dans un nouveau tableau trié |
| Taille de l'entrée | Complexité dans le pire des cas |
|---|---|
| tableaux de \(n_{1}\) et \(n_{2}\) éléments | linéaire en \(O(n_{1} + n_{2})\) |
def fusion(tab1, tab2):
i1 = 0
i2 = 0
tab3 = []
while i1 < len(tab1) and i2 < len(tab2):
if tab1[i1] <= tab2[i2]:
tab3.append(tab1[i1])
i1 += 1
else:
tab3.append(tab2[i2])
i2 += 1
while i1 < len(tab1):
tab3.append(tab1[i1])
i1 += 1
while i2 < len(tab2):
tab3.append(tab2[i2])
i2 += 1
return tab3
def fusion2(tab1, tab2):
i1 = 0
i2 = 0
tab3 = []
while i1 < len(tab1) or i2 < len(tab2):
if (i1 == len(tab1)) or (i2 < len(tab2) and tab2[i2] < tab1[i1]):
tab3.append(tab2[i2])
i2 += 1
else:
tab3.append(tab1[i1])
i1 += 1
return tab3
Complexité quadratique⚓︎
Définition
Une complexité quadratique dans le pire des cas signifie qu'il existe une constante \(k\) telle que : \(C(n) \leqslant k n^{2}\).
C'est une complexité acceptable uniquement pour de petites valeurs de \(n\) (inférieures à 1000).
Tri par sélection
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Tableau | Non vide | Rien | Trie en place tab dans l'ordre croissant |
| Taille de l'entrée | Complexité dans le pire des cas (dans tous les cas en fait) |
|---|---|
| tableau de \(n\) éléments | quadratique en \(O(n^{2})\) |
def tri_selection(tab):
for i in range(len(tab)):
imin = i
for j in range(i + 1, len(tab)):
if tab[i] < tab[imin]:
imin = i
tmp = tab[i]
tab[i] = tab[imin]
tab[imin] = tmp
Tri par insertion
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Tableau | Non vide | Rien | Trie en place tab dans l'ordre croissant |
| Taille de l'entrée | Complexité dans le pire des cas | Complexité dans le cas moyen | Complexité dans le meilleur des cas |
|---|---|---|---|
| tableau de \(n\) éléments | quadratique en \(O(n^{2})\) si tab dans l'ordre décroissant |
quadratique en \(O(n^{2})\) | linéaire en \(O(n)\) si tab déjà dans l'ordre croissant |
def tri_insertion(tab):
for i in range(1, len(tab)):
elt = tab[i]
j = i - 1
while j >= 0 and tab[j] > elt:
tab[j + 1] = tab[j]
j = j - 1
tab[j + 1] = elt
def tri_insertion(tab):
for i in range(1, len(tab)):
elt = tab[i]
j = i
while j > 0 and tab[j - 1] > elt:
tab[j] = tab[j - ]
j = j - 1
tab[j] = elt
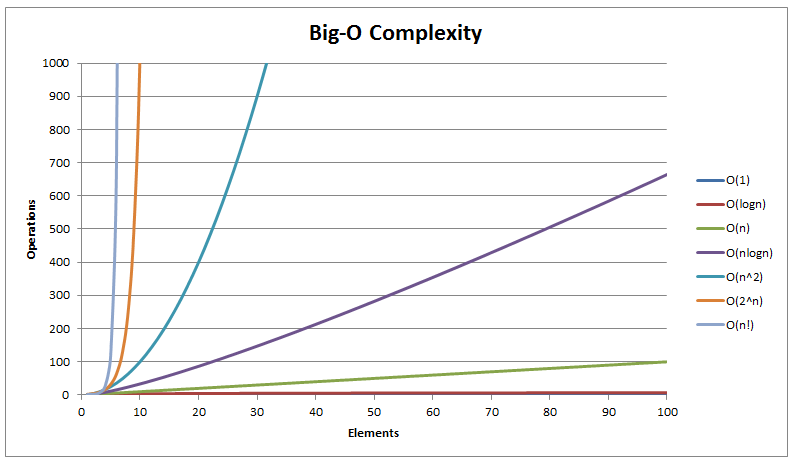
Comparaison des algorithmes de tri classiques
La complexité en temps du tri fusion d'un tableau de taille \(n\) est linéarithmique, en \(O(n \log_{2}(n))\).
Cette complexité est optimale pour les tris par comparaison de deux éléments.
Le tri fusion est plus efficace que les algorithmes de tri vus en classe de première qui sont de complexité quadratique, en \(O(n^{2})\). Le tri rapide est un autre algorithme Diviser pour Régner, très efficace. L'implémentation, plus délicate, sera vue en TP.
| Algorithme de tri d'un tableau de taille \(n\) | Complexité dans le meilleur des cas | Complexité dans le cas moyen | Complexité dans le pire des cas |
|---|---|---|---|
| tri par sélection | \(O(n^{2})\) | \(O(n^{2})\) | \(O(n^{2})\) |
| tri par insertion | \(O(n)\) (tableau déjà trié) | \(O(n^{2})\) (ordre inverse) | \(O(n^{2})\) |
| tri par bulles | \(O(n^{2})\) | \(O(n^{2})\) | \(O(n^{2})\) |
| tri fusion | \(O(n\log_{2}(n))\) | \(O(n\log_{2}(n))\) | \(O(n\log_{2}(n))\) |
| tri rapide | \(O(n\log_{2}(n))\) | \(O(n\log_{2}(n))\) | \(O(n^{2})\) (tableau déjà trié) |
Dictionnaires⚓︎
Complexité linéaire⚓︎
Histogramme d'une chaîne de caractères
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Chaîne de caractères | Non vide | Dictionnaire | Renvoie le dictionnaire des occurrences des caractères dans la chaîne |
| Taille de l'entrée | Complexité dans le pire des cas |
|---|---|
| Chaîne de \(n\) éléments | linéaire en \(O(n)\) |
def histogramme(chaine):
histo = dict()
for c in chaine:
if c in histo:
histo[c] = histo[c] + 1
else:
histo[c] = 1
return histo
Listes chaînées⚓︎
Complexité linéaire⚓︎
Longueur d'une liste chaînée
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Liste chaînée | Non vide | Entier | Renvoie la longueur d'une liste chaînée |
| Taille de l'entrée | Complexité dans le pire des cas (et dans tous les cas) |
|---|---|
| liste chaînée de \(n\) éléments | linéaire en \(O(n)\) |
On donne un code avec une liste chaînée non mutable implémentée par des tuples et une interface fonctionnelle du type Liste.
def longueur(lis):
if liste_vide(lis):
return 0
return 1 + longueur(queue(lis))
def longueur(lis):
lon = 0
courant = lis # élément en tête
while not liste_vide(courant):
# si besoin traitement sur tete(courant)
lon = lon + 1
courant = queue(courant)
return lon
Piles⚓︎
Complexité linéaire⚓︎
Somme des éléments d'une pile
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Pile | Non vide | Entier | Renvoie la somme des éléments d'une pile d'entiers et reconstruit la pile initiale |
| Taille de l'entrée | Complexité dans le pire des cas (et dans tous les cas) |
|---|---|
| pile de \(n\) éléments | linéaire en \(O(n)\) |
On donne un code avec une pile implémentée dans une interface objet.
def somme_pile(p):
s = 0
tmp = Pile()
while not p.pile_vide():
x = p.depiler()
s = s + x
tmp.empiler(x)
# on reconstruit la pile initiale
while not tmp.pile_vide():
x = tmp.depiler()
p.empiler(x)
return s
Files⚓︎
Complexité linéaire⚓︎
Inverser une file avec une pile
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| File | Non vide | File | Renvoie une autre file aves les éléments dans l'ordre inverse |
| Taille de l'entrée | Complexité dans le pire des cas (et dans tous les cas) |
|---|---|
| file de \(n\) éléments | linéaire en \(O(n)\) |
On donne un code avec une file et une pile implémentées dans des interfaces objets.
def inverser_file(f):
p = Pile()
tmp = File()
while not f.file_vide():
x = f.defiler()
p.empiler(x)
tmp.enfiler(x)
finv = File()
while not p.pile_vide():
x = p.depiler()
finv.enfiler(x)
# on reconstruit la file initiale
while not tmp.file_vide():
x = tmp.defiler()
f.enfiler(x)
return finv
Arbres binaires⚓︎
Complexité linéaire (par rapport à la taille de l'arbre)⚓︎
Taille d'un arbre binaire
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Arbre binaire | Aucune | Entier | Renvoie le nombre de noeuds stockés dans l'arbre |
Avec une classe Noeud, l'arbre binaire vide représenté par None et une interface fonctionnelle. Pour l'interface voir le cours
def taille(arbre):
"""Renvoie la taille de l'arbre"""
if arbre is None:
return 0
return 1 + taille(arbre.gauche) + taille(arbre.droit)
Avec une classe AB d''arbre binaire qui utilise une classe Noeud. Pour l'interface voir le cours.
⚠️ Bien lire l'interface, c'est-à-dire la définition des attributs et des méthodes de la classe avant de coder.
def taille(self):
"""Renvoie la hauteur de l'arbre"""
if self.est_vide():
return 0
return 1 + self.gauche().taille() + self.droit().taille()
Hauteur d'un arbre binaire
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Arbre binaire | Aucune | Entier | Renvoie le nombre de noeuds sur le plus long chemin entre la racine et une feuille |
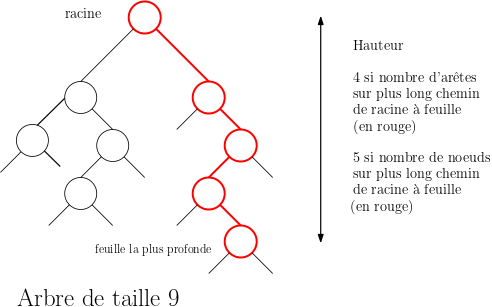
Avec une classe Noeud, l'arbre binaire vide représenté par None et une interface fonctionnelle. Pour l'interface voir le cours
def hauteur(arbre):
"""Renvoie la hauteur de l'arbre"""
if arbre is None:
return 0
return 1 + max(hauteur(arbre.gauche), hauteur(arbre.droit))
Avec une classe AB d''arbre binaire qui utilise une classe Noeud. Pour l'interface voir le cours
⚠️ Bien lire l'interface, c'est-à-dire la définition des attributs et des méthodes de la classe avant de coder.
def hauteur(self):
"""Renvoie la hauteur de l'arbre"""
if self.est_vide():
return 0
return 1 + max(self.gauche().hauteur(), self.droit().hauteur())
Parcours en profondeur d'un arbre binaire
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Arbre binaire | Aucune | Dépend du traitement sur les noeuds | Parcourt tous les noeuds de l'arbre depuis la racine en explorant d'abord les enfants (gauche puis droite) |
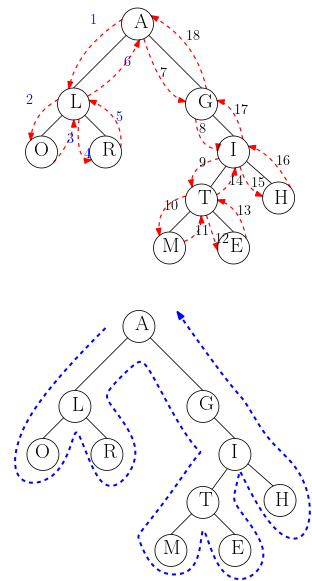
Selon l'ordre de traitement du noeud par rapport au parcours des sous-arbres, on distingue trois types de parcours en profondeur.
Les codes sont donnés pour des arbres binaires représentés avec une classe Noeud, l'arbre binaire vide représenté par None et une interface fonctionnelle.
Dans le parcours en profondeur préfixe, on traite l'élément stocké dans le noeud avant de parcourir les sous-arbres.
def parcours_prefixe(arbre):
if arbre is None: # cas de l'arbre vide
return
traitement(arbre.racine) # on traite le noeud racine
parcours_prefixe(arbre.gauche) # on parcourt récursivement le fils gauche
parcours_prefixe(arbre.droit) # on parcourt récursivement le fils droit
Pour l'arbre binaire donné en exemple, avec un parcours préfixe, l'ordre de traitement des éléments stockés serait :
A - L - O - R - G - I - T - M - E - H
Dans le parcours en profondeur infixe, on taite l'élément stocké dans le noeud entre le parcours du sous-arbre/fils gauche et le parcours du sous-arbre/fils droit.
def parcours_infixe(arbre):
if arbre is None: # cas de l'arbre vide
return
parcours_infixe(arbre.gauche) # on parcourt récursivement le fils gauche
traitement(arbre.racine) # on traite le noeud racine
parcours_infixe(arbre.droit) # on parcourt récursivement le fils droit
Pour l'arbre binaire donné en exemple, avec un parcours infixe, l'ordre de traitement des éléments stockés serait :
O - L - R - A - G - M - T - E - I - H
Dans le parcours en profondeur suffixe appelé aussi parcours en profondeur postfixe, on taite l'élément stocké dans le noeud après le parcours du sous-arbre/fils gauche et le parcours du sous-arbre/fils droit.
def parcours_postfixe(arbre):
if arbre is None: # cas de l'arbre vide
return
parcours_postfixe(arbre.gauche) # on parcourt récursivement le fils gauche
parcours_postfixe(arbre.droit) # on parcourt récursivement le fils droit
traitement(arbre.racine) # on traite le noeud racine
Pour l'arbre binaire donné en exemple, avec un parcours postfixe, l'ordre de traitement des éléments stockés serait :
O - R - L - M - E - T - H - I - G - A
Parcours en largeur d'un arbre binaire
| Entrée | Précondition | Sortie | Spécification |
|---|---|---|---|
| Arbre binaire | Aucune | Dépend du traitement sur les noeuds | Parcourt tous les noeuds de l'arbre depuis la racine en explorant d'abord les frères (de gauche à droite) |
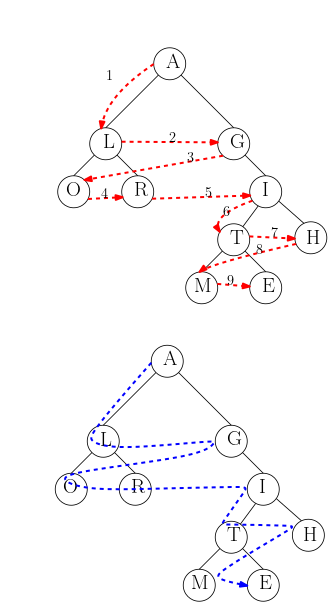
On commence par enfiler l'arbre (s'il est non vide), puis tant que la file n'est pas vide :
- on défile l'arbre en tête de file ;
- on traite l'élément stocké dans le noeud racine puis on enfile les fils/sous-arbres (gauche puis droite) s'ils existent.
On donne un code avec interface fonctionnelle pour arbre binaire et file.
def parcours_largeur(arbre):
f = creer_file()
if arbre is not None:
enfiler(f, arbre)
while not file_vide(f):
a = defiler(f)
traitement(a.racine)
if a.gauche is not None:
f.enfiler(a.gauche)
if a.droit is not None:
f.enfiler(a.droit)
Arbres binaires de recherche⚓︎
Complexité logarithmique (par rapport à la taille de l'arbre)⚓︎
Recherche d'un élément dans un arbre binaire de recherche
Le nombre de comparaisons effectuées lors de la recherche d'un élément dans un arbre binaire est au plus égal au nombre de noeuds dans le plus long chemin reliant la racine à une feuille. La complexité en temps de la recherche est donc majorée par une constante fois la hauteur de l'arbre binaire de recherche. On rappelle que la hauteur \(h\) d'un arbre binaire de taille \(n\) vérifie l'inégalité \(\log_{2}(n)< h \leqslant n\). La complexité en temps de la recherche dans un arbre binaire de recherche dépend donc de la forme de l'arbre, avec deux cas extrêmes :
- Pire forme : dans un arbre binaire dégénéré, par un exemple un peigne, on aura une complexité linéaire en \(O(n)\) comme pour une recherche séquentielle dans une liste chaînée.
- Meilleure forme : dans un arbre binaire presque complet ou parfait, on aura une complexité logarithmique, en \(O(\log_{2}(n))\) donc bien meilleure.
| Forme de l'arbre binaire | Complexité de la recherche d'un élément par rapport à la taille |
|---|---|
| dégénéré | linéaire |
| presque complet ou parfait | logarithmique |
def recherche(abr, elt):
"""Renvoie un booléen indiquant si elt est stocké dans un noeud
de l'arbre binaire de recherche abr
"""
if est_vide(abr):
return False
elif elt < abr.element:
return recherche(abr.gauche, elt)
elif elt > abr.element:
return recherche(abr.droit, elt)
else:
return True
def recherche(self, elt):
"""Renvoie un booléen indiquant si elt est stocké dans un noeud
de l'arbre binaire de recherche self de la classe ABR
"""
if self.est_vide():
return False
elif elt < self.element_racine():
return self.gauche().recherche(elt):
elif elt > abr.element:
return self.droit().recherche(elt):
else:
return True
Ajout d'un élément dans un arbre binaire de recherche
Pour ajouter un élément dans un arbre binaire présentant la propriété d'arbre binaire de recherche on effectue la même descente dans l'arbre que pour la recherche. Deux situations finales sont possibles :
- Situation 1 : on atteint un arbre dont le noeud racine contient déjà l'élément stocké, dans ce cas :
- si on ne veut pas de doublons dans l'arbre binaire initial : on termine sans rien faire
- si on accepte les doublons dans l'arbre binaire initial : on poursuit alors l'ajout dans le fils/sous-arbre gauche
- Situation 2 : on atteint un arbre vide :
- on crée alors à cet emplacement libre un arbre binaire dont le noeud racine contient l'élément
| Forme de l'arbre binaire | Complexité de l'ajout d'un élément par rapport à la taille |
|---|---|
| dégénéré | linéaire |
| presque complet ou parfait | logarithmique |
def ajoute(abr, elt):
"""Renvoie un nouvel arbre binaire de recherche construit par ajout de elt comme feuille dans l'arbre binaire de recherche abr
"""
if abr is None:
return Noeud(None, elt, None)
elif elt <= abr.element:
return Noeud(ajoute(abr.gauche, elt), abr.element, abr.droit)
else:
return Noeud(abr.gauche, abr.element, ajoute(abr.droit, elt))
def ajoute(self, elt):
"""Ajoute elt dans une feuille de l'arbre binaire de recherche
Maintient la propriété d'arbre binaire de recherche."""
if self.est_vide():
self.racine = Noeud(ABR(), elt, ABR())
elif elt <= self.element_racine():
self.gauche().ajoute(elt)
else:
self.droit().ajoute(elt)
Algorithmes sur les graphes⚓︎
Complexité linéaire⚓︎
Parcours en largeur d'un graphe (BFS)
On considère un graphe orienté ou non orienté et un sommet s du graphe.
Le parcours en largeur de graphe ou Breadth First Search (BFS) en anglais est une version de l'algorithme générique de parcours de graphe où les sommets en attente sont stockés dans une file. On marque un sommet comme découvert lorsqu'on l'insère dans la file d'attente.
L'algorithme découvre les sommets atteignables depuis s par couches successives :
- d'abord le sommet
sen couche 0 - puis les sommets voisins de
sen couche 1 - puis les voisins de voisins de
squi n'ont pas encore été découverts en couche 2 - ...
- puis les voisins des sommets de la couche
i- 1qui n'ont pas encore découverts en couchei - etc ... jusqu'à ce que tous les sommets atteignables depuis
ssoient découverts
Voici une implémentation du parcours en largeur (BFS) sous la forme d'une fonction Python qui prend en paramètres le sommet source s et le graphe qui est un objet de la classe Graphe.
def bfs(sommet, graphe):
"""Parcours en largeur d'un graphe instance de la classe Graphe
depuis un sommet source"""
decouvert = {s: False for s in graphe.sommets()}
en_attente = File()
decouvert[sommet] = True
en_attente.enfiler(sommet)
while not en_attente.file_vide():
s = en_attente.defiler()
for v in graphe.voisins(s):
if not decouvert[v]:
decouvert[v] = True
en_attente.enfiler(v)
Complexité
On considère un graphe orienté ou non orienté et un sommet s du graphe.
Le parcours en largeur a une complexité en \(O(n_{s} + m_{s})\) où \(n_{s}\) et \(m_{s}\) sont respectivement le nombre de sommets et le nombre d'arcs atteignables depuis le sommet source s.
C'est optimal car \(O(n_{s} + m_{s})\) est aussi le coût de lecture du graphe et il faut au moins lire le graphe pour le parcourir !
Parcours en profondeur d'un graphe (DFS)
On considère un graphe orienté ou non orienté et un sommet s du graphe.
Le parcours en profondeur de graphe ou Depth First Search (DFS) en anglais est une version de l'algorithme générique de parcours de graphe où les sommets en attente sont stockés dans une pile. On marque un sommet comme découvert lorsqu'on l'extrait de la pile.
L'algorithme découvre les sommets atteignables depuis s en s'éloignant toujours plus de la source tant que c'est possible ou en revenant en arrière sinon :
- d'abord le sommet
s - puis un des sommets voisins de
s, jusque là c'est comme pour le parcours en largeur - mais ensuite au lieu de découvir un des autres voisins de
s, le parcours en profondeur va chercher à découvrir l'un des voisins encore non découverts du dernier sommet découvertv(le sommet de la pile). S'il n'y en a pas, il revient sur ses pas jusqu'au prédécesseur devpour explorer d'autres voisins non découverts de ce sommet ou encore revenir en arrière ... jusqu'à ce que tous les sommets atteignables soient découverts.
Voici une implémentation du parcours en profondeur (DFS) sous la forme d'une fonction Python qui prend en paramètres le sommet source s et le graphe qui est un objet de la classe Graphe.
def dfs(sommet, graphe):
"""Parcours en profondeur d'un graphe instance de la classe Graphe
depuis un sommet source s"""
decouvert = {s: False for s in graphe.sommets()}
en_attente = Pile()
en_attente.empiler(sommet)
while not en_attente.pile_vide():
s = en_attente.depiler()
if not decouvert[s]:
decouvert[s] = True
for v in graphe.voisins(s):
if not decouvert[v]:
en_attente.empiler(v)
Complexité
On considère un graphe orienté ou non orienté et un sommet s du graphe.
Le parcours en profondeur a une complexité en \(O(n_{s} + m_{s})\) où \(n_{s}\) et \(m_{s}\) sont respectivement le nombre de sommets et le nombre d'arcs atteignables depuis le sommet source s.
C'est optimal car \(O(n_{s} + m_{s})\) est aussi le coût de lecture du graphe et il faut au moins lire le graphe pour le parcourir