Parcours (Bac 🎯)⚓︎

Ce cours est mis à disposition selon les termes de la Licence Creative Commons Attribution - Pas d'Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 International.

Sources et crédits pour ce cours
Pour préparer ce cours, j'ai utilisé :
- le manuel NSI chez Ellipses de Balabonski, Conchon, Filliâtre, Nguyen
- le cours de Gilles Lassus
- le cours de Cédric Gouygou
- le livre Algorithms illuminated Part 2 de Tim Roughgarden.
🔖 Synthèse de ce qu'il faut retenir pour le bac
Parcours générique de graphe⚓︎
Point de cours 1 : parcours générique de graphe
On considère un graphe orienté ou non et un sommet s du graphe.
Définition
On dit qu'un sommet w est atteignable depuis s s'il existe un chemin dans le graphe d'origine s et d'extrémité w.
Naturellement on souhaiterait répondre à la question : quels sont les sommets atteignables depuis s par un chemin dans le graphe ?
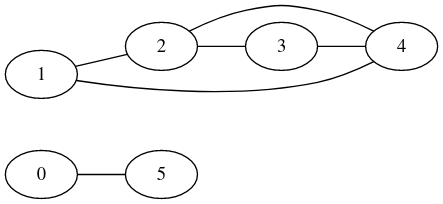
Par exemple dans le graphe non orienté ci-dessus, les sommets d'étiquettes 2, 3 et 4 sont atteignables depuis le sommet d'étiquette 1 mais pas les sommets étiquetés 0 et 5.
Un algorithme permettant de répondre à ce problème est un parcours de graphe.
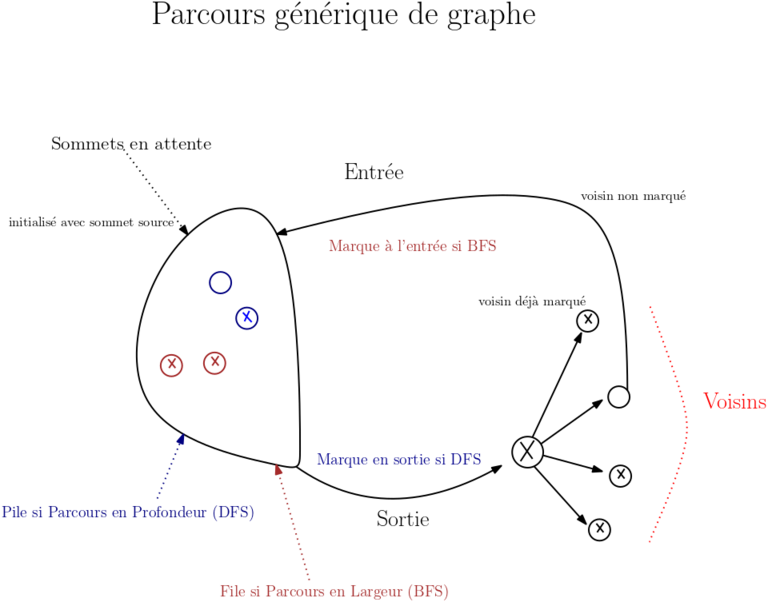
Si on divise les sommets en deux catégories : ceux qui ont déjà été découverts par le parcours et les autres , alors on peut décrire simplement un algorithme générique de parcours de graphe :
On marque le sommet `s` comme découvert
Tant qu'il existe un arc v -> w tel que v est marqué comme découvert et w comme non découvert :
On choisit un tel arc
On marque son extrémité w comme sommet découvert
A chaque itération de la boucle, un sommet passe de l'ensemble des sommets non découverts à l'ensemble des sommets découverts. À la fin de l'algorithme les sommets marqués comme découverts sont exactement ceux atteignables depuis s.
preuve
L'algorithme se termine car l'ensemble des arcs dont l'origine est découverte et l'extrémité non comptera au plus un nombre d'éléments égal au nombre d'arcs et un arc est retiré de cet ensemble à chaque tour de boucle.
Par construction les sommets marqués comme découverts à la fin de l'algorithme sont bien des extrémités de chemins d'orisgine s et sont donc atteignables depuis s.
Hypothèse (H) : Supposons qu'il existe un sommet w atteignable depuis s et qui n'est pas marqué comme découvert à la fin de l'algorithme.
Par hypothèse, w est atteignable depuis s, donc il existe un chemin s -> x0 ... xp -> xq .... -> w. Si w n'est pas marqué comme découvert, alors dans ce chemin il existe un arc xp -> xq avec xp marqué comme découvert (au pire c'est s) et xq non marqué comme découvert. Mais c'est impossible car l'arc xp -> xq aurait forcément été sélectionné par l'algorithme dans la boucle et le sommet xq aurait été alors marqué comme découvert. On aboutit à une contradiction.
L'hypothèse (H) était donc fausse, et on conclut que sa négation est vraie : tout sommet w atteignable depuis s est marqué comme exploré à la fin de l'algorithme. C'est un exemple de raisonnement par l'absurde.
💡 En pratique, on va stocker dans un ensemble tous les sommets en attente de sélection par la boucle : tant que cet ensemble est non vide, on retire un sommet à marquer et on rajoute dans l'ensemble ses voisins (ou successeurs pour un graphe orienté) qui ne sont pas encore marqués comme découverts. Nous allons présenter deux algorithmes classiques de parcours de graphe qui diffèrent par la façon de stocker les sommets en attente.
Parcours en largeur de graphe (BFS)⚓︎
Une file pour stocker les sommets en attente⚓︎
Une file pour les sommets en attente
Dans l'algorithme de parcours en largeur, les sommets en attente sont stockés dans une file qui est une structure First In First Out c'est-à-dire que les sommets sortent de la file dans leur ordre d'entrée.
On va utiliser une interface minimale du type abstrait file implémenté avec une deque de Python, ce qui permet de garantir un coût constant pour l'entrée et la sortie de file.
Algorithme de parcours en largeur d'un graphe⚓︎
Point de cours 2 : parcours en largeur d'un graphe (BFS)
On considère un graphe orienté ou non orienté et un sommet s du graphe.
Le parcours en largeur de graphe ou Breadth First Search (BFS) en anglais est une version de l'algorithme générique de parcours de graphe où les sommets en attente sont stockés dans une file. On marque un sommet comme découvert lorsqu'on l'insère dans la file d'attente.
L'algorithme découvre les sommets atteignables depuis s par couches successives :
- d'abord le sommet
sen couche 0 - puis les sommets voisins de
sen couche 1 - puis les voisins de voisins de
squi n'ont pas encore été découverts en couche 2 - ...
- puis les voisins des sommets de la couche
i- 1qui n'ont pas encore découverts en couchei - etc ... jusqu'à ce que tous les sommets atteignables depuis
ssoient découverts
Voici une implémentation du parcours en largeur (BFS) sous la forme d'une fonction Python qui prend en paramètres le sommet source s et le graphe qui est un objet de la classe Graphe.
def bfs(sommet, graphe):
"""Parcours en largeur d'un graphe instance de la classe Graphe
depuis un sommet source"""
decouvert = {s: False for s in graphe.sommets()}
en_attente = File()
decouvert[sommet] = True
en_attente.enfiler(sommet)
while not en_attente.file_vide():
s = en_attente.defiler()
for v in graphe.voisins(s):
if not decouvert[v]:
decouvert[v] = True
en_attente.enfiler(v)
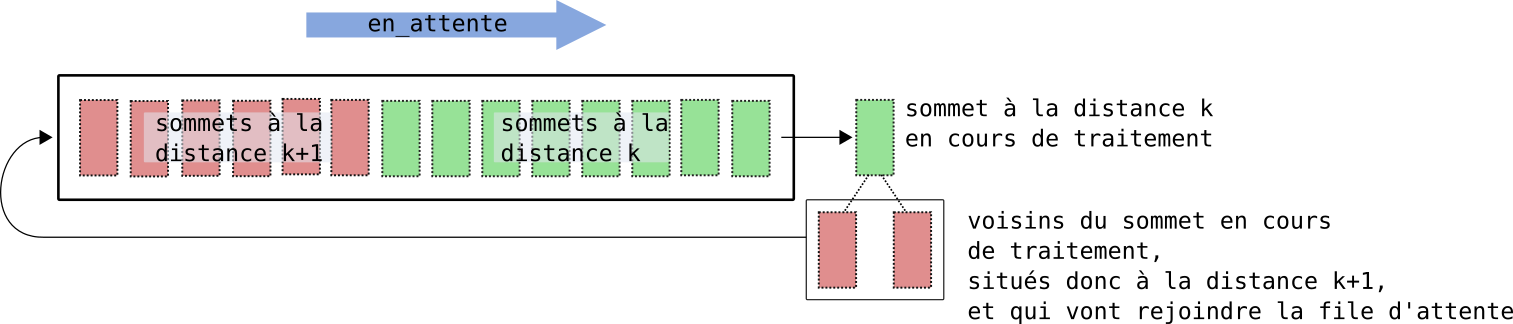
Contenu de la file d'attente
Source : schéma de Gilles Lassus
À chaque instant, la file d'attente contient des sommets à la distance k+1 et à la distance k du sommet source.
Exemple de parcours en largeur
On considère le graphe non orienté ci-dessous :
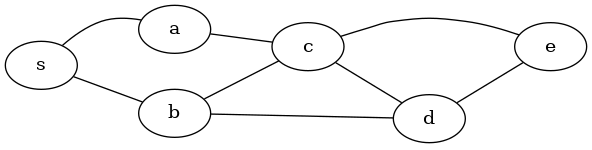
Le graphe est représenté dans une variable g1 par un dictionnaire de listes d'adjacences :
>>> g1 = Graphe(['s', 'a', 'b', 'c', 'e', 'd'])
>>> g1.ajoute_arc('s', 'a')
>>> g1.ajoute_arc('s', 'b')
>>> g1.ajoute_arc('a', 'c')
>>> g1.ajoute_arc('c', 'd')
>>> g1.ajoute_arc('b', 'c')
>>> g1.ajoute_arc('b', 'd')
>>> g1.ajoute_arc('c', 'e')
>>> g1.ajoute_arc('d', 'e')
>>> g1.adjacents
{'s': ['a', 'b'],
'a': ['s', 'c'],
'b': ['s', 'c', 'd'],
'c': ['a', 'd', 'b', 'e'],
'e': ['c', 'd'],
'd': ['c', 'b', 'e']}
Déroulons l'appel bfs('s', g1) :
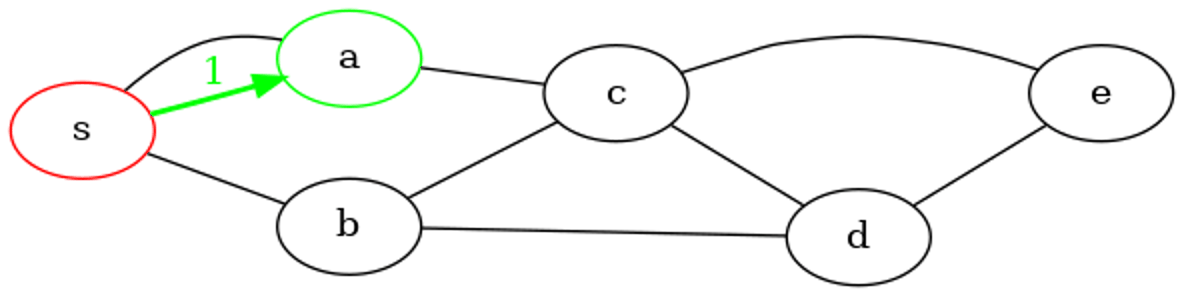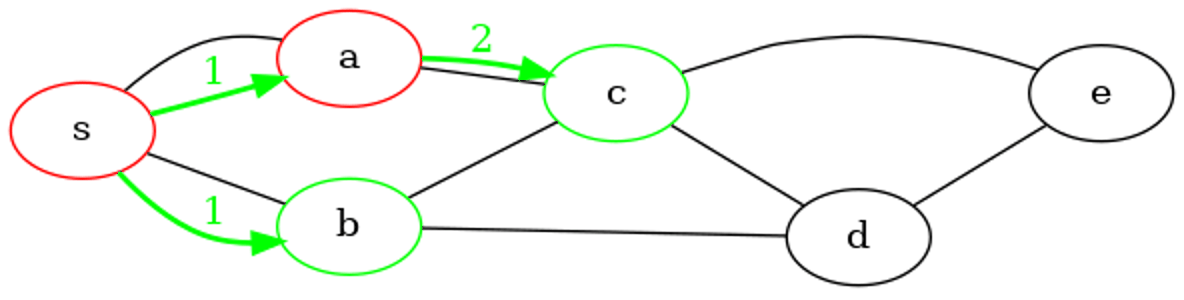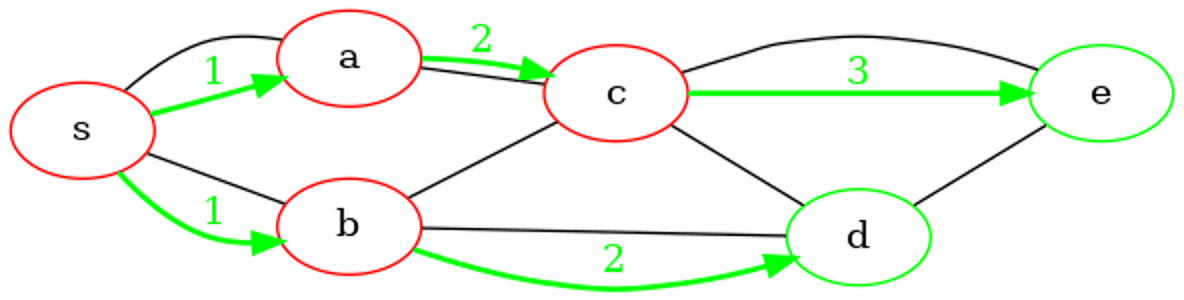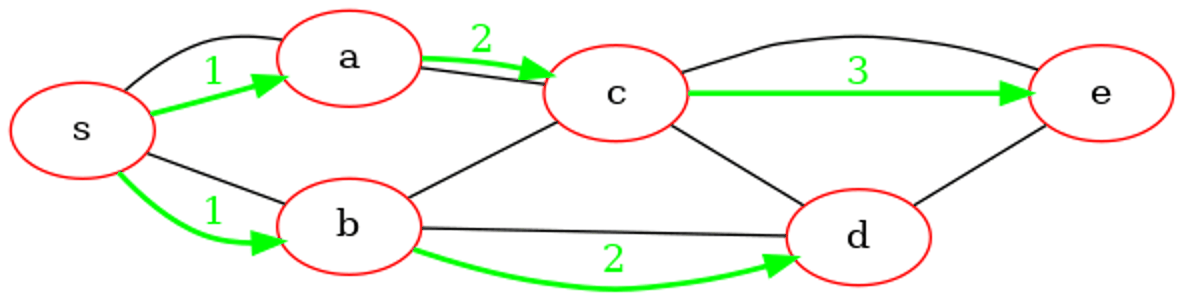
File d'attente : debut : s: fin
Sommet extrait de la file d'attente : s
Découvert, ajout en file d'attente de : a
Découvert, ajout en file d'attente de : b
--------------------------------------------------------------------------------
File d'attente : debut : a - b: fin
Sommet extrait de la file d'attente : a
Découvert, ajout en file d'attente de : c
--------------------------------------------------------------------------------
File d'attente : debut : b - c: fin
Sommet extrait de la file d'attente : b
Découvert, ajout en file d'attente de : d
--------------------------------------------------------------------------------
File d'attente : debut : c - d: fin
Sommet extrait de la file d'attente : c
Découvert, ajout en file d'attente de : e
--------------------------------------------------------------------------------
File d'attente : debut : d - e: fin
Sommet extrait de la file d'attente : d
--------------------------------------------------------------------------------
File d'attente : debut : e: fin
Sommet extrait de la file d'attente : e
--------------------------------------------------------------------------------
Trace d'exécution en animation gif :
Point de cours 3 : complexité du parcours en largeur d'un graphe
On considère un graphe orienté ou non orienté et un sommet s du graphe.
L'algorithme de parcours en largeur est une déclinaison du parcours générique dont on a prouvé qu'il découvrait exactement les sommets atteignables depuis le sommet source s.
De plus, le parcours en largeur a une complexité en \(O(n_{s} + m_{s})\) où \(n_{s}\) et \(m_{s}\) sont respectivement le nombre de sommets et le nombre d'arcs atteignables depuis le sommet source s.
Une complexité optimale
C'est optimal car \(O(n_{s} + m_{s})\) est aussi le coût de lecture du graphe et il faut au moins lire le graphe pour le parcourir !
preuve
Chaque sommet atteignable depuis s est inséré et retiré exactement une fois dans la file d'attente avec un coût constant garanti par la structure de la file : donc déjà un coût en \(O(n_{s})\).
Ensuite, chaque arc est examiné une fois (graphe orienté) ou deux fois (graphe non orienté) dans la boucle for interne, quand l'une de ses extrémités est le sommet extrait de la file, ce qui rajoute un coût en \(O(m_{s})\).
Au total, on a bien un coût en \(O(n_{s} + m_{s})\).
Un parcours en largeur augmenté pour calculer la distance au sommet source⚓︎
Point de cours 4 : parcours en largeur et calcul de distance
On considère un graphe orienté ou non orienté, non pondéré, et un sommet s du graphe.
Définition
On dit qu'un sommet w est à distance d du sommet source s si le plus court chemin d'origine s et d'extrémité w a pour longueur d, en nombre d'arcs.
On a vu dans le point 2 de cours, que le parcours en largeur découvre les sommets par couches de plus en éloignées du sommet source s. Les sommets découverts dans la couche d étant des voisins des sommets découverts dans la couche d - 1, on peut démontrer par récurrence que les sommets découverts dans la couche d sont exactement ceux à distance d du sommet source s.
On peut alors augmenter l'algorithme de parcours en largeur avec un dictionnaire distance permettant de mémoriser la distance à la source des sommets découverts. On initialise ce dictionnaire avec des distances infinies pour tous les sommets sauf le sommet source de distance nulle. On peut ainsi calculer les distances à la source de tous les sommets atteignables.
def bfs_distance(sommet, graphe):
decouvert = {s: False for s in graphe.sommets()}
distance = {s:float('inf') for s in graphe.sommets()}
en_attente = File()
decouvert[sommet] = True
distance[sommet] = 0
en_attente.enfiler(sommet)
while not en_attente.file_vide():
s = en_attente.defiler()
for v in graphe.voisins(s):
if not decouvert[v]:
decouvert[v] = True
distance[v] = distance[s] + 1
en_attente.enfiler(v)
return distance
Exercice⚓︎
Exercice 13
On considère un graphe non orienté modélisant des liaisons entre aéroports américains.
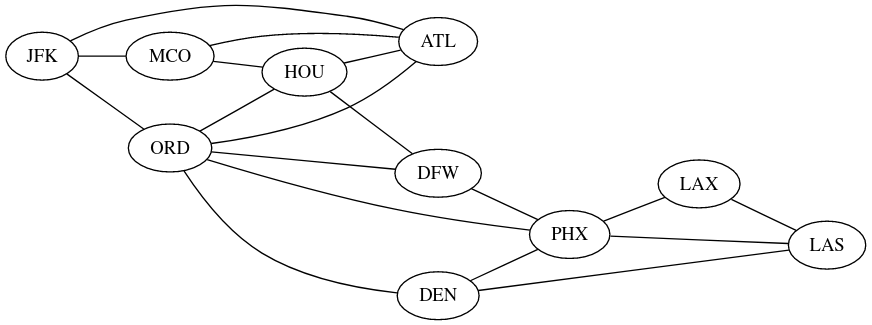
Ce graphe est représenté par le dictionnaire de listes d'adjacences ci-dessous :
{'JFK': ['MCO', 'ATL', 'ORD'],
'MCO': ['JFK', 'ATL', 'HOU'],
'ORD': ['DEN', 'HOU', 'DFW', 'PHX', 'JFK', 'ATL'],
'DEN': ['ORD', 'PHX', 'LAS'],
'HOU': ['ORD', 'ATL', 'DFW', 'MCO'],
'DFW': ['PHX', 'ORD', 'HOU'],
'PHX': ['DFW', 'ORD', 'DEN', 'LAX', 'LAS'],
'ATL': ['JFK', 'HOU', 'ORD', 'MCO'],
'LAX': ['PHX', 'LAS'],
'LAS': ['DEN', 'LAX', 'PHX']}
Question 1
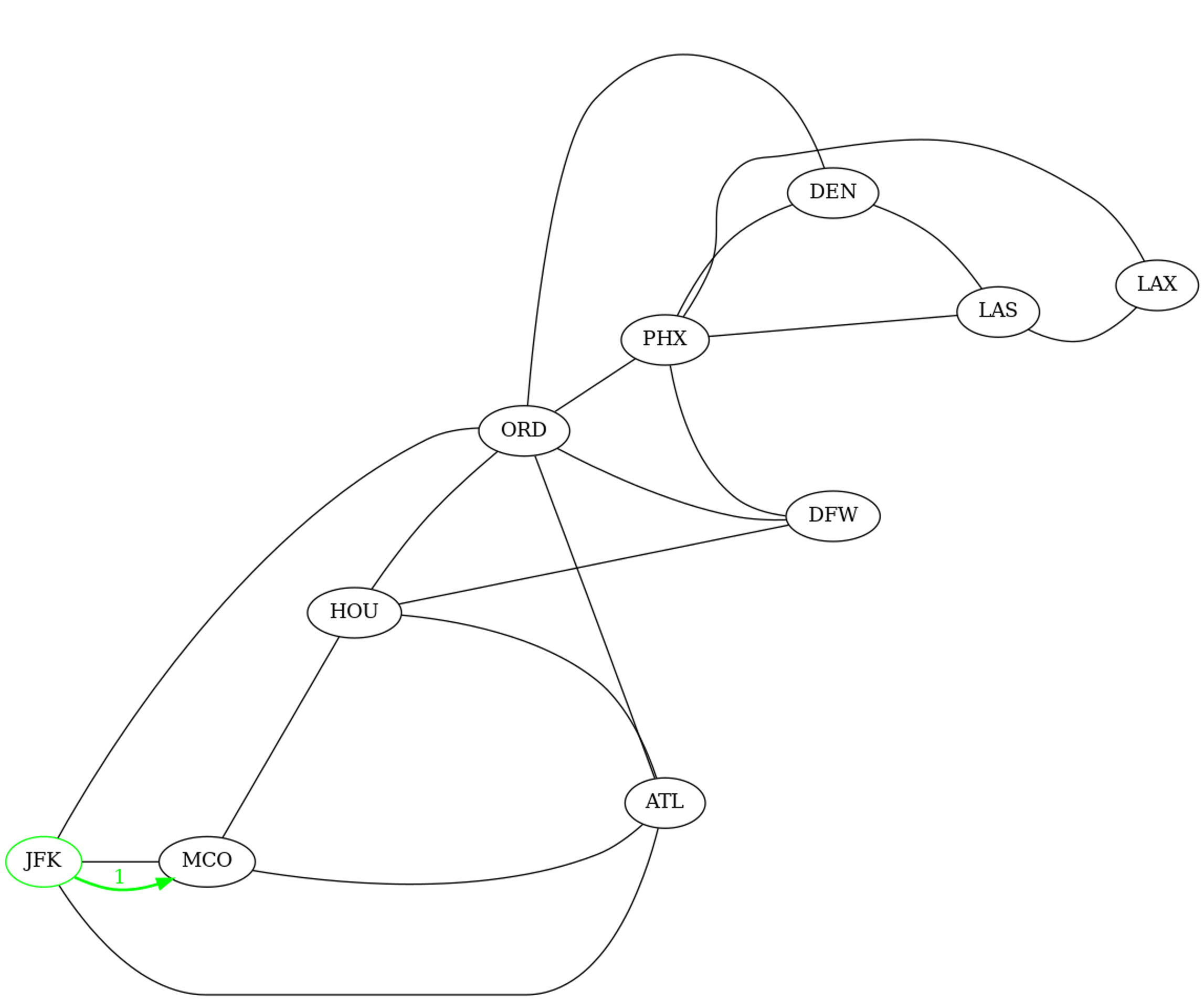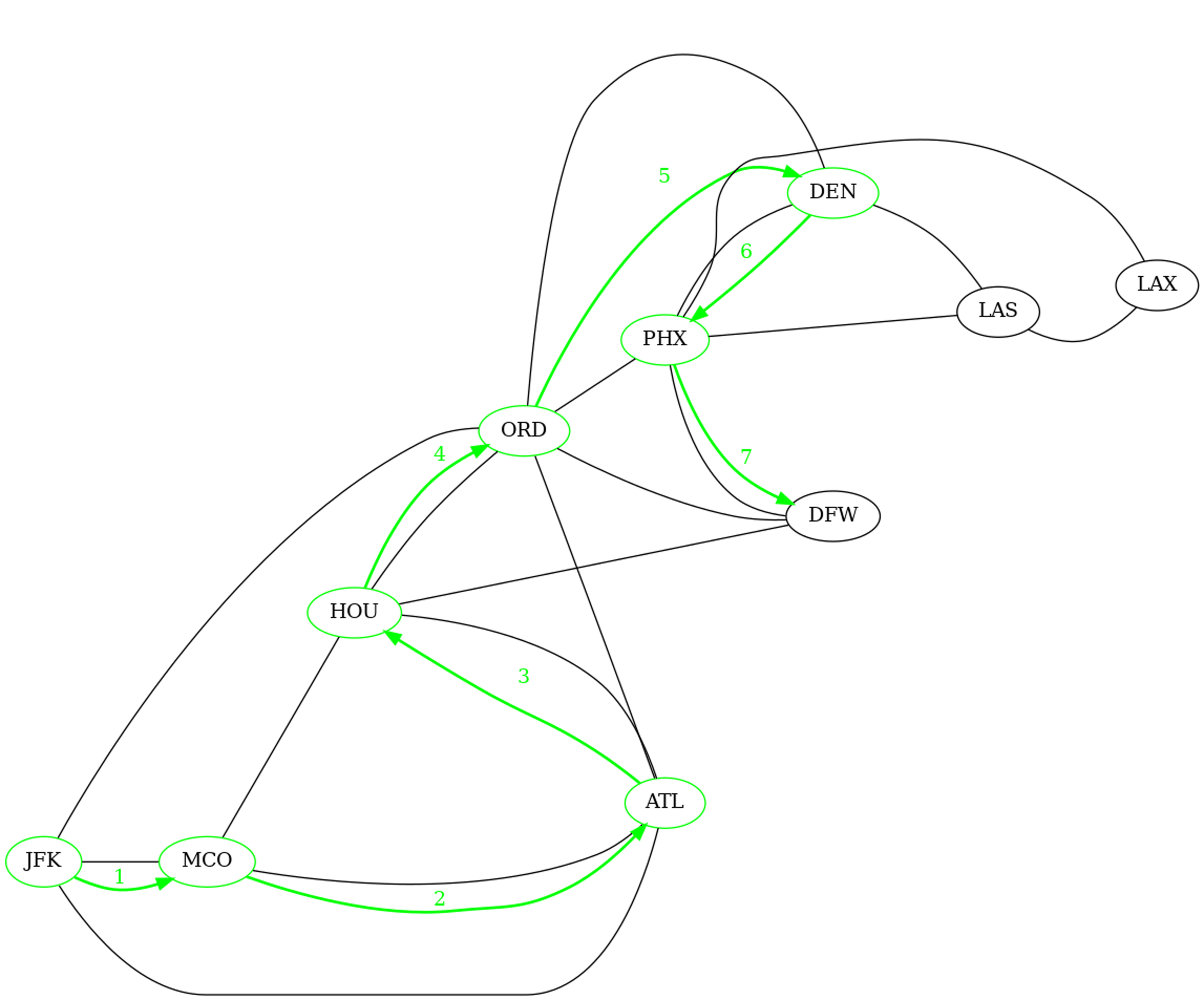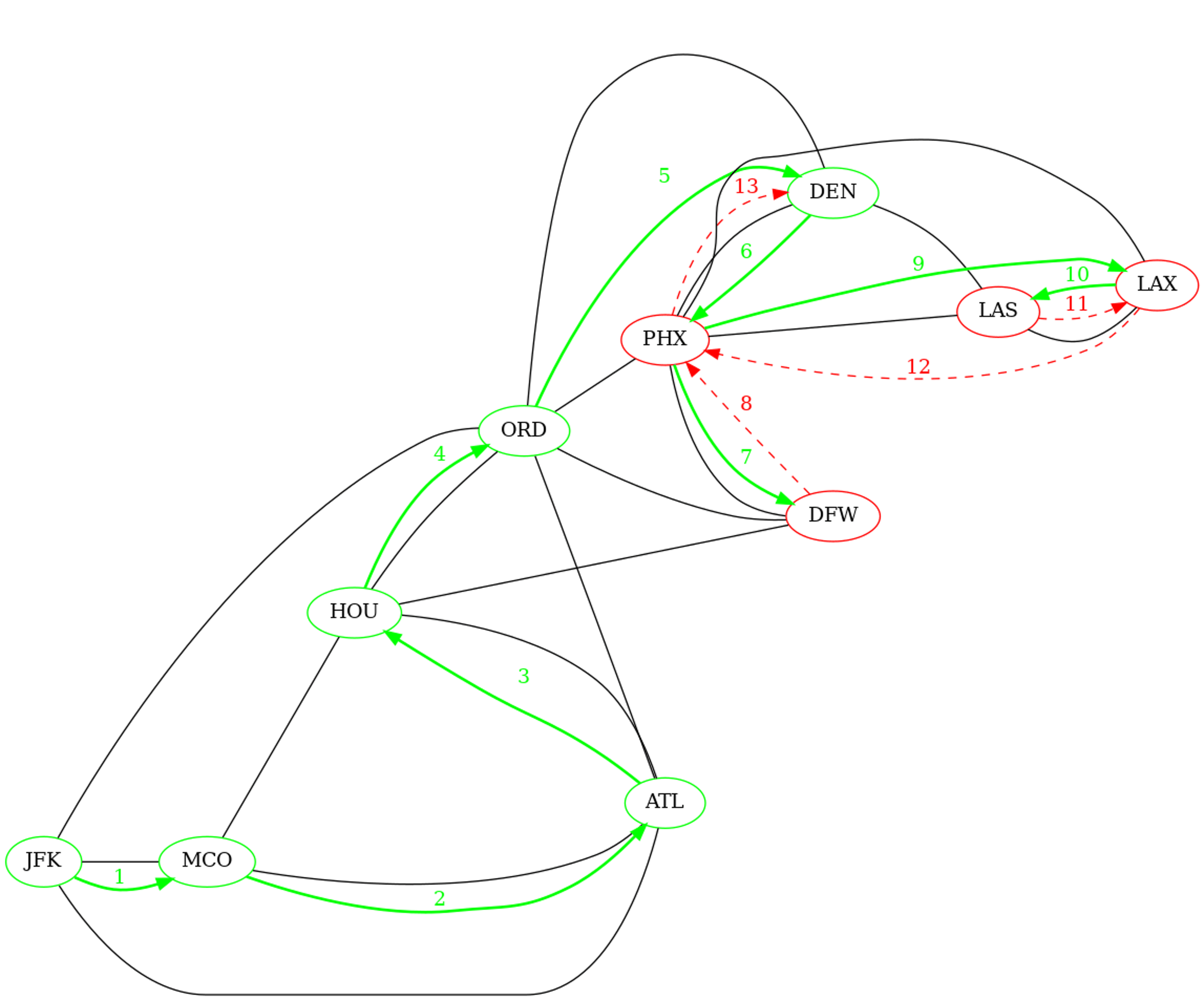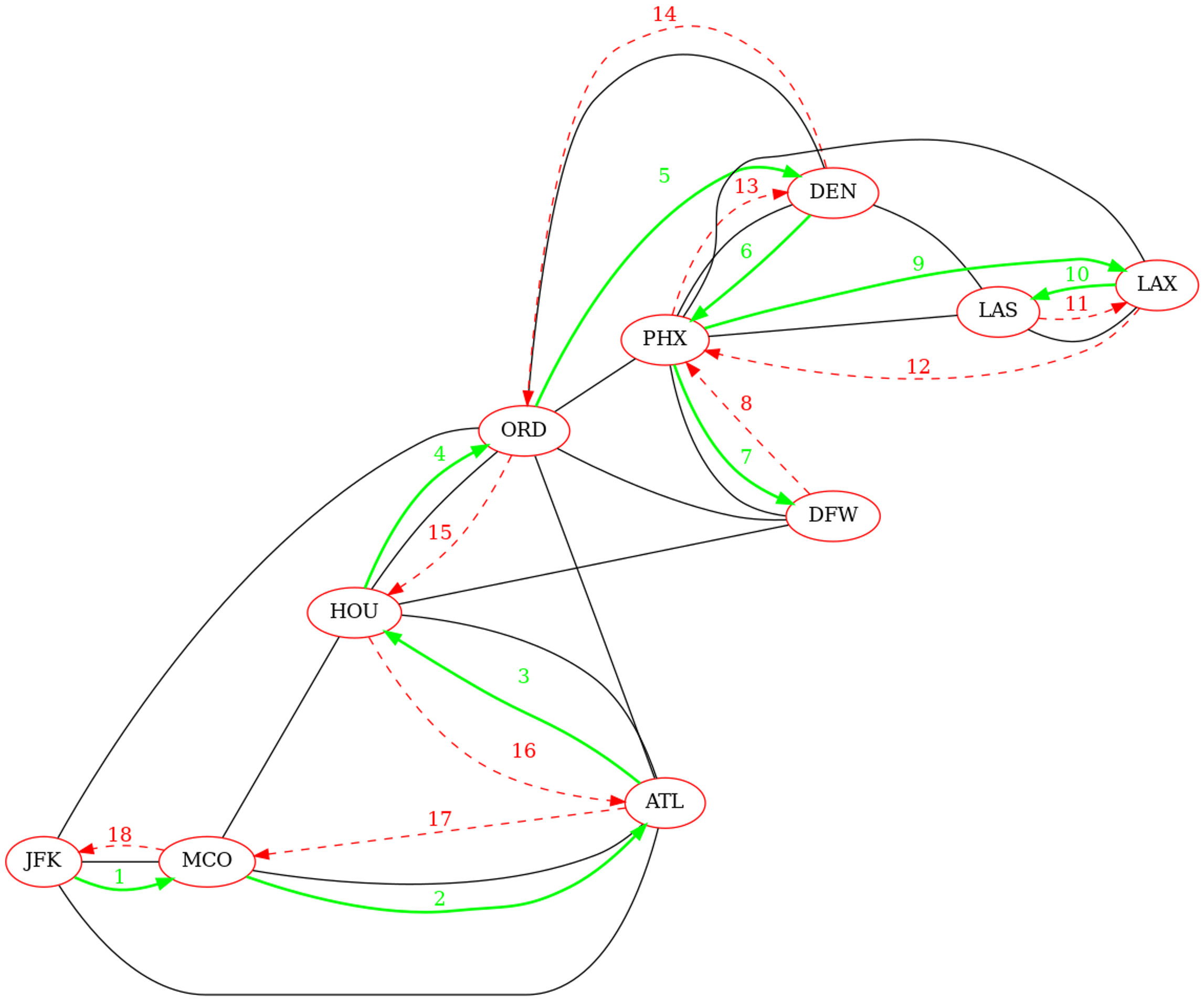
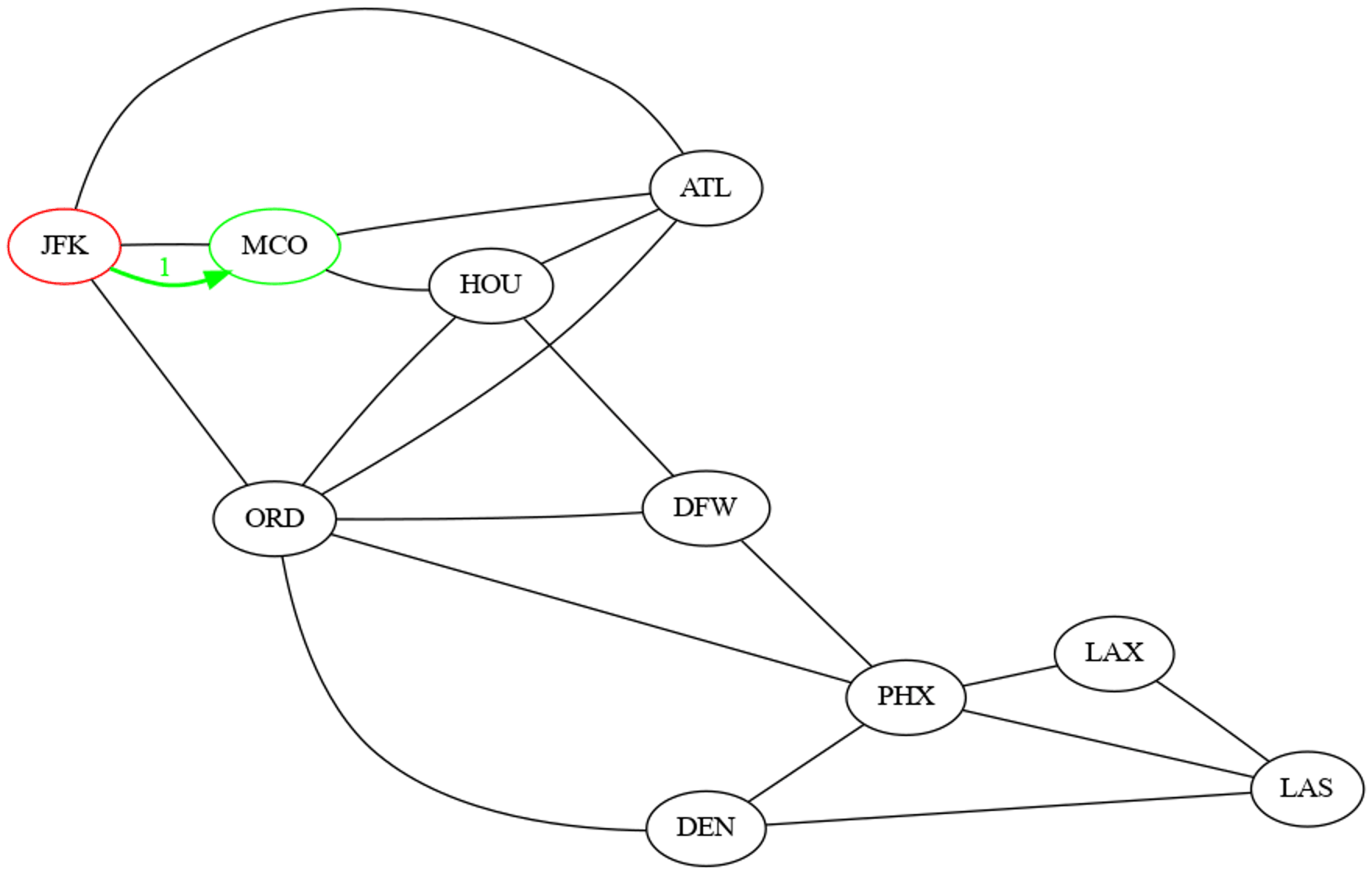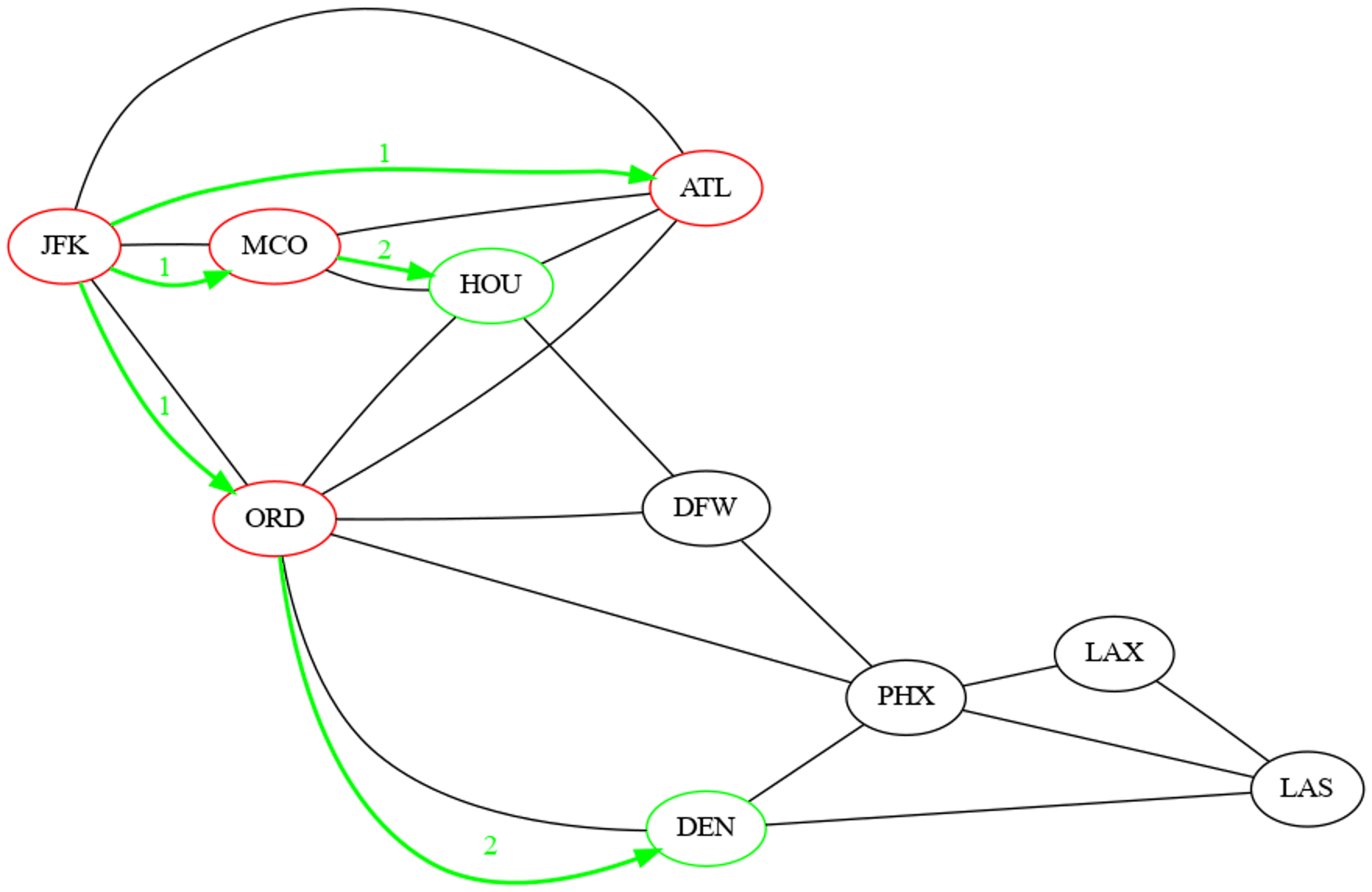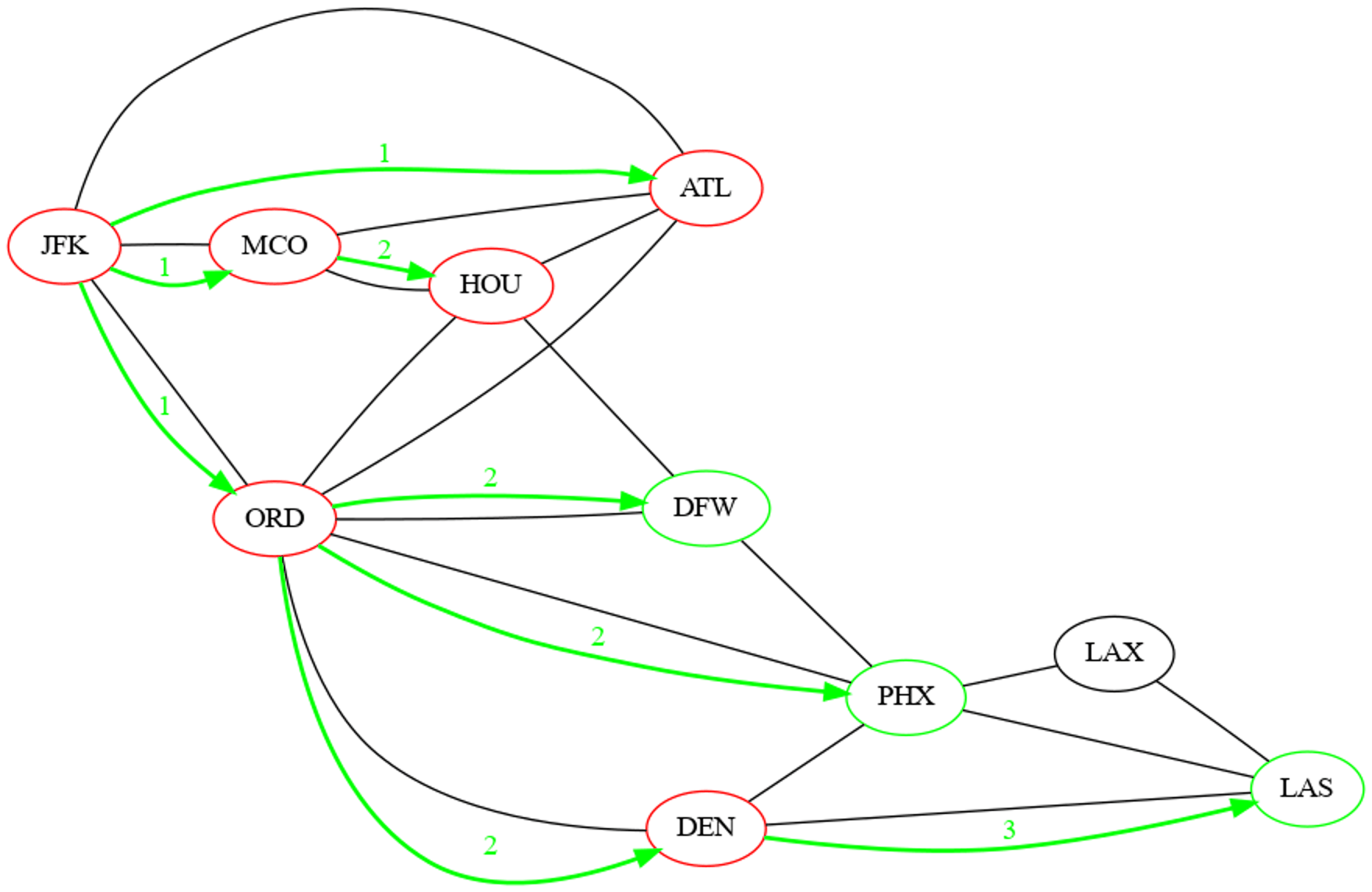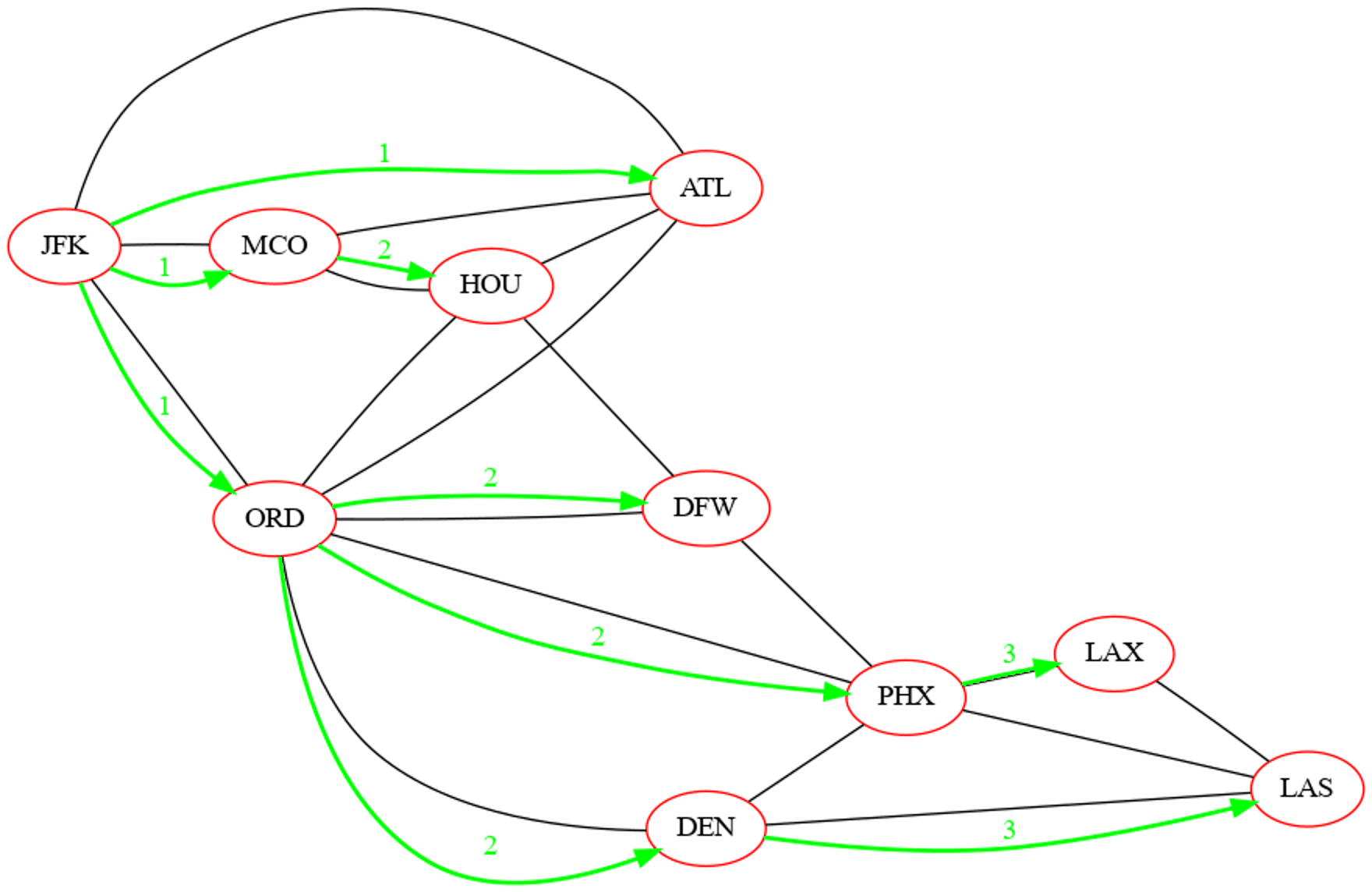
Déterminer l'ordre de découverte et la distance à la source de tous les sommets du graphe, calculés par un parcours en largeur initié depuis le sommets étiqueté JFK.
| Sommet | Ordre de découverte | Distance à la source |
|---|---|---|
| 'JFK' | 1 | 0 |
| 'MCO' | 2 | 1 |
| 'ATL' | 3 | 1 |
| 'ORD' | 4 | 1 |
| 'HOU' | 5 | 2 |
| 'DEN' | 6 | 2 |
| 'DFW' | 7 | 2 |
| 'PHX' | 8 | 2 |
| 'LAS' | 9 | 3 |
| 'LAX' | 10 | 3 |
Parcours en profondeur de graphe (DFS)⚓︎
Une pile pour stocker les sommets en attente⚓︎
Une pile pour les sommets en attente
Dans l'algorithme de parcours en profondeur, les sommets en attente sont stockés dans une pile qui est une structure Last In First Out c'est-à-dire que les premiers sommets à sortir de la pile sont les dernier entrés.
On va utiliser une interface minimale du type abstrait pile, implémenté avec les bonnes méthodes du type list de Python qui garantissent un coût constant pour l'entrée et la sortie de pile.
Algorithme de parcours en profondeur d'un graphe⚓︎
Point de cours 5 : parcours en profondeur d'un graphe (DFS)
On considère un graphe orienté ou non orienté et un sommet s du graphe.
Le parcours en profondeur de graphe ou Depth First Search (DFS) en anglais est une version de l'algorithme générique de parcours de graphe où les sommets en attente sont stockés dans une pile. On marque un sommet comme découvert lorsqu'on l'extrait de la pile.
Attention
On a choisi de garder le terme découvert introduit dans le parcours générique mais dans le cas du parcours en profondeur on devrait parler plutôr de visité. La structure de données où sont stockés les sommets en attente est une pile Last In First Out donc l'ordre de visite (sortie de la structure) est l'inverse de celui de découverte (entrée dans la pile). Dans un parcours en largeur, la structure est First In First Out et l'ordre de découverte et de visite sont les mêmes.
L'algorithme découvre les sommets atteignables depuis s en s'éloignant toujours plus de la source tant que c'est possible ou en revenant en arrière sinon :
- d'abord le sommet
s - puis un des sommets voisins de
s, jusque là c'est comme pour le parcours en largeur - mais ensuite au lieu de découvir un des autres voisins de
s, le parcours en profondeur va chercher à découvrir l'un des voisins encore non découverts du dernier sommet découvertv(le sommet de la pile). S'il n'y en a pas, il revient sur ses pas jusqu'au prédécesseur devpour explorer d'autres voisins non découverts de ce sommet ou encore revenir en arrière ... jusqu'à ce que tous les sommets atteignables soient découverts.
Voici une implémentation du parcours en profondeur (DFS) sous la forme d'une fonction Python qui prend en paramètres le sommet source s et le graphe qui est un objet de la classe Graphe.
def dfs(sommet, graphe):
"""Parcours en profondeur d'un graphe instance de la classe Graphe
depuis un sommet source s"""
decouvert = {s: False for s in graphe.sommets()}
en_attente = Pile()
en_attente.empiler(sommet)
while not en_attente.pile_vide():
s = en_attente.depiler()
if not decouvert[s]:
decouvert[s] = True
for v in graphe.voisins(s):
if not decouvert[v]:
en_attente.empiler(v)
Exemple de parcours en profondeur
On considère le même graphe non orienté que pour le parcours en largeur avec un schéma légèrement différent.
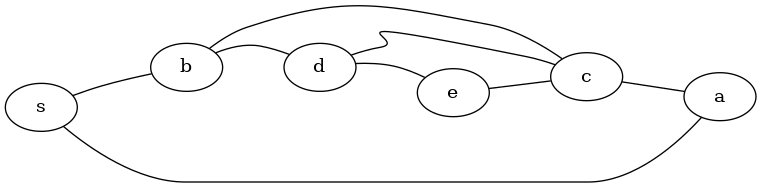
Le graphe est représenté dans une variable g1 par un dictionnaire de listes d'adjacences comme dans l'exemple de parcours en largeur.
>>> g1.adjacents
{'s': ['a', 'b'],
'a': ['s', 'c'],
'b': ['s', 'c', 'd'],
'c': ['a', 'd', 'b', 'e'],
'e': ['c', 'd'],
'd': ['c', 'b', 'e']}
Déroulons l'appel dfs('s', g1). On peut remarquer que tous les sommets atteignables passent par la pile :
un sommet est marqué comme découvert exactement une fois, mais il peut être ajouté plusieurs fois comme voisin d'autres sommets découverts. Dans ce cas lorsqu'on le retire et qu'il est déjà découvert, on ne le traite pas.
Pile : Début -> s -> Fin
Sommet extrait de la pile : s
Sommet marqué comme découvert : s
Ajout sur la pile : a
Ajout sur la pile : b
--------------------------------------------------------------------------------
Pile : Début -> b -> a -> Fin
Sommet extrait de la pile : b
Sommet marqué comme découvert : b
Ajout sur la pile : c
Ajout sur la pile : d
--------------------------------------------------------------------------------
Pile : Début -> d -> c -> a -> Fin
Sommet extrait de la pile : d
Sommet marqué comme découvert : d
Ajout sur la pile : c
Ajout sur la pile : e
--------------------------------------------------------------------------------
Pile : Début -> e -> c -> c -> a -> Fin
Sommet extrait de la pile : e
Sommet marqué comme découvert : e
Ajout sur la pile : c
--------------------------------------------------------------------------------
Pile : Début -> c -> c -> c -> a -> Fin
Sommet extrait de la pile : c
Sommet marqué comme découvert : c
Ajout sur la pile : a
--------------------------------------------------------------------------------
Pile : Début -> a -> c -> c -> a -> Fin
Sommet extrait de la pile : a
Sommet marqué comme découvert : a
--------------------------------------------------------------------------------
Pile : Début -> c -> c -> a -> Fin
Sommet extrait de la pile : c
--------------------------------------------------------------------------------
Pile : Début -> c -> a -> Fin
Sommet extrait de la pile : c
--------------------------------------------------------------------------------
Pile : Début -> a -> Fin
Sommet extrait de la pile : a
--------------------------------------------------------------------------------
Trace d'exécution en animation gif. Les flèches vertes représentent les sauts en avant et les flèches rouges les retours en arrière. On peut noter qu'un même sommet peut être traversé plusieurs fois (au moins deux fois : découverte et retour en arrière).
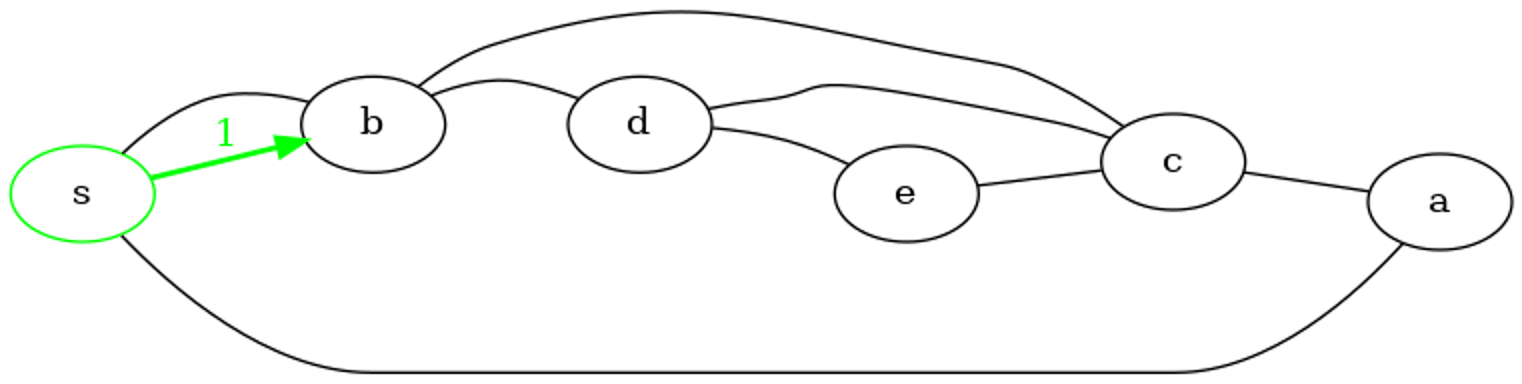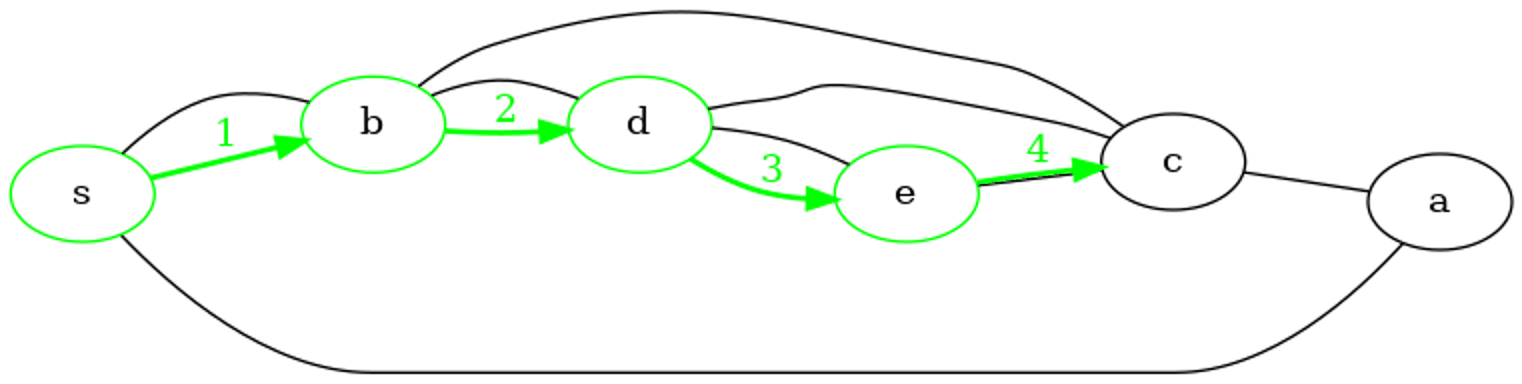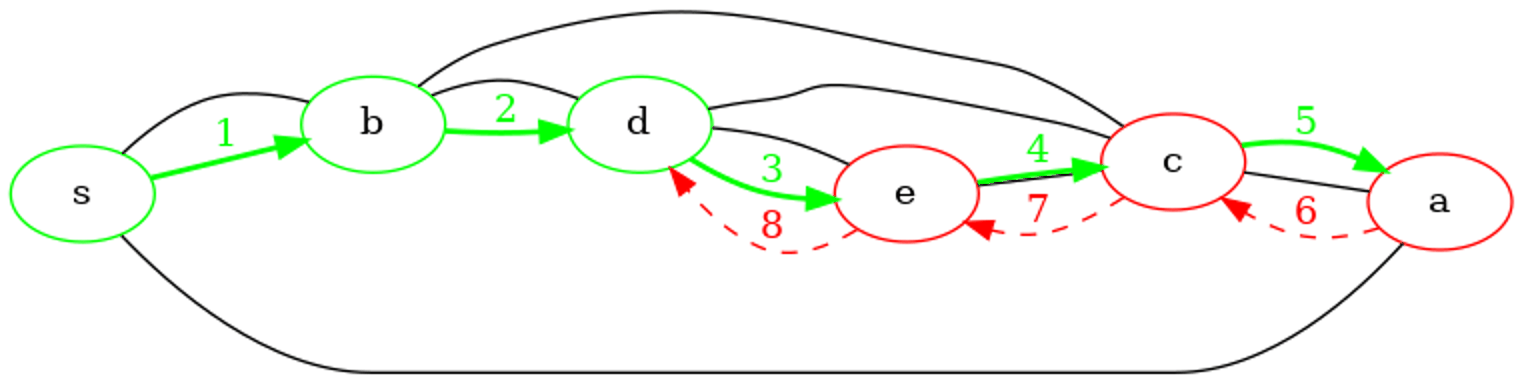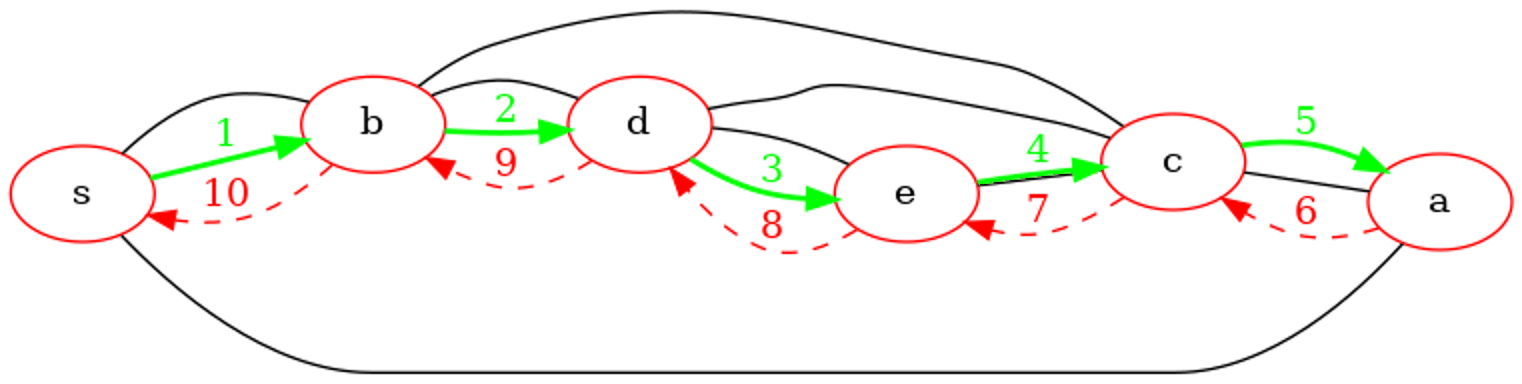
Point de cours 6 : complexité du parcours en profondeur d'un graphe
On considère un graphe orienté ou non orienté et un sommet s du graphe.
L'algorithme de parcours en profondeur est une déclinaison du parcours générique dont on a prouvé qu'il découvrait exactement les sommets atteignables depuis le sommet source s.
De plus, le parcours en profondeur a la même complexité que le parcours en largeur, en \(O(n_{s} + m_{s})\) où \(n_{s}\) et \(m_{s}\) sont respectivement le nombre de sommets et le nombre d'arcs atteignables depuis le sommet source s.
Une complexité optimale
C'est optimal car \(O(n_{s} + m_{s})\) est aussi le coût de lecture du graphe et il faut au moins lire le graphe pour le parcourir !
preuve
Chaque sommet atteignable depuis s est retiré de la pile et marqué comme découvert exactement une fois avec un coût constant garanti par la structure de la pile : donc déjà un coût en \(O(n_{s})\).
Ensuite, chaque arc est examiné une fois dans la boucle for interne, quand l'une de ses extrémités est un sommet extrait de la pile découvert pour la première fois, ce qui rajoute un coût en \(O(m_{s})\). Un sommet peut être ajouté (puis retiré) plusieurs fois dans la pile mais au plus une fois par arc donc \(m_{s}\) fois.
Au total, on a bien un coût en \(O(n_{s} + m_{s})\).
Une version récursive du parcours en profondeur⚓︎
Point de cours 7 : parcours en profondeur récursif
On considère un graphe orienté ou non orienté et un sommet s du graphe.
La pile des sommets en attente d'un parcours en profondeur peut être simulée par la pile des appels imbriqués d'une fonction récursive.
On peut alors donner une version récursive élégante du parcours en profondeur :
def dfs_rec(sommet, graphe, decouvert):
"""Parcours en profondeur d'un graphe instance de la classe Graphe
depuis un sommet source.
Decouvert est un dictionnaire associant à chaque sommet sa marque de visite"""
decouvert[sommet] = True
for v in graphe.voisins(sommet):
if not decouvert[v]:
dfs_rec(v, graphe, decouvert)
Quel est l'intérêt du parcours en profondeur ?
L'ordre de découverte des sommets atteignables par le parcours en profondeur ne permet pas de calculer les distances à la source comme le parcours en largeur. Mais la version récursive du parcours en profondeur permet de comprendre qu'un sommet est traversé pour la dernière fois (fin de l'appel récursif) lorsque tous les sommets atteignables depuis lui ont été découverts.
C'est une propriété intéressante : en inversant cet ordre, et si le graphe ne contient pas de cycle, on peut énumérer les sommets du graphe atteignables depuis le sommet source, dans un ordre ou un sommet n'est jamais cité avant un sommet atteignable depuis lui. On parle d'ordre topologique.
Si le graphe est orienté et modélise des contraintes avec un arc partant d'un sommet représentant une tâche vers une tâche qui doit être effectuée après, alors l'ordre topologique est celui dans lequel toutes les tâches peuvent être effectuées en respectant les contraintes de précédence.
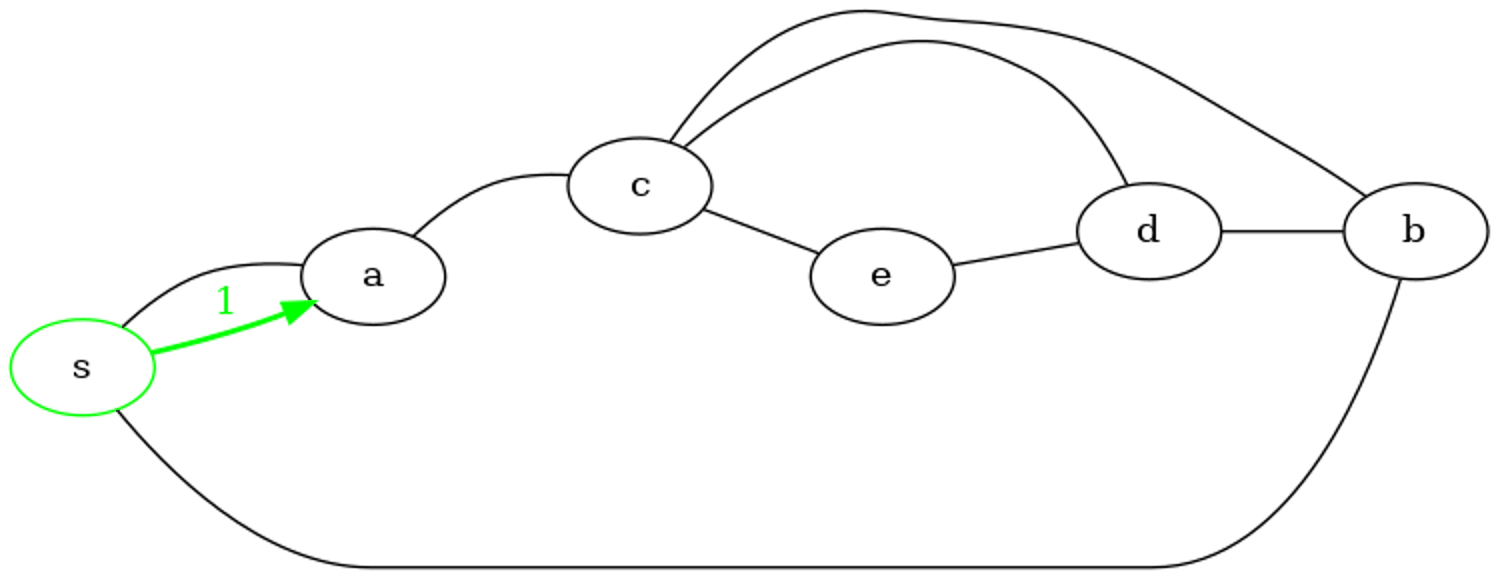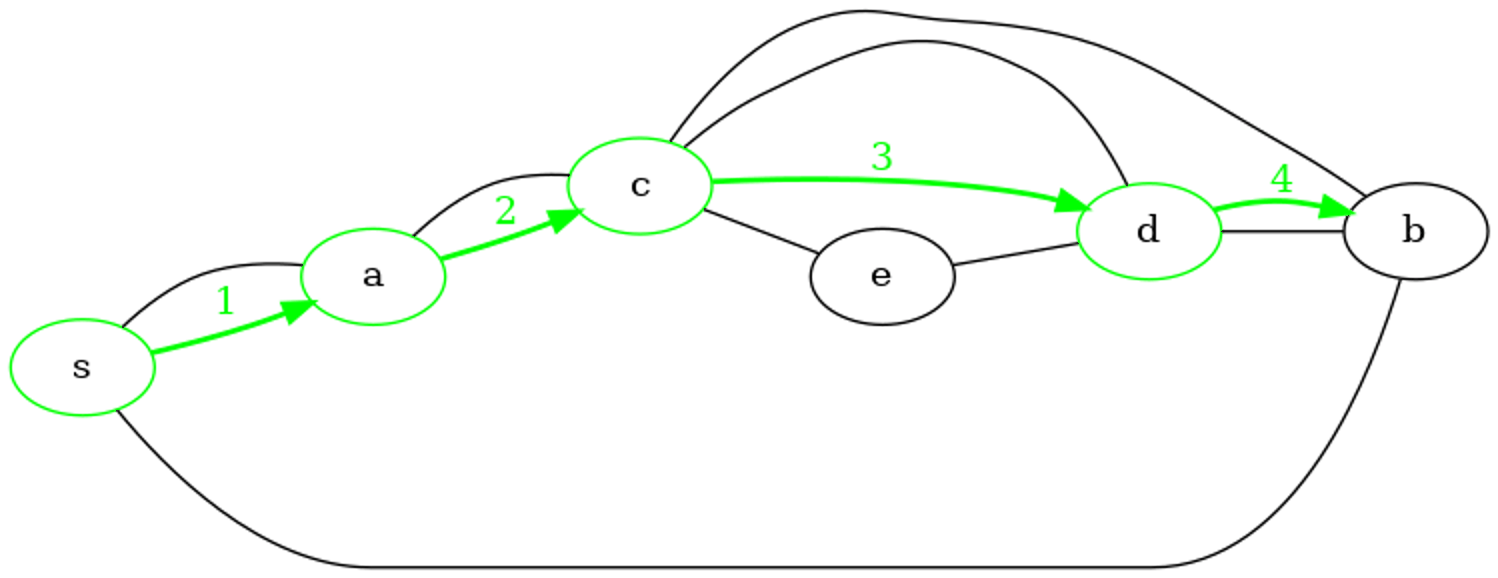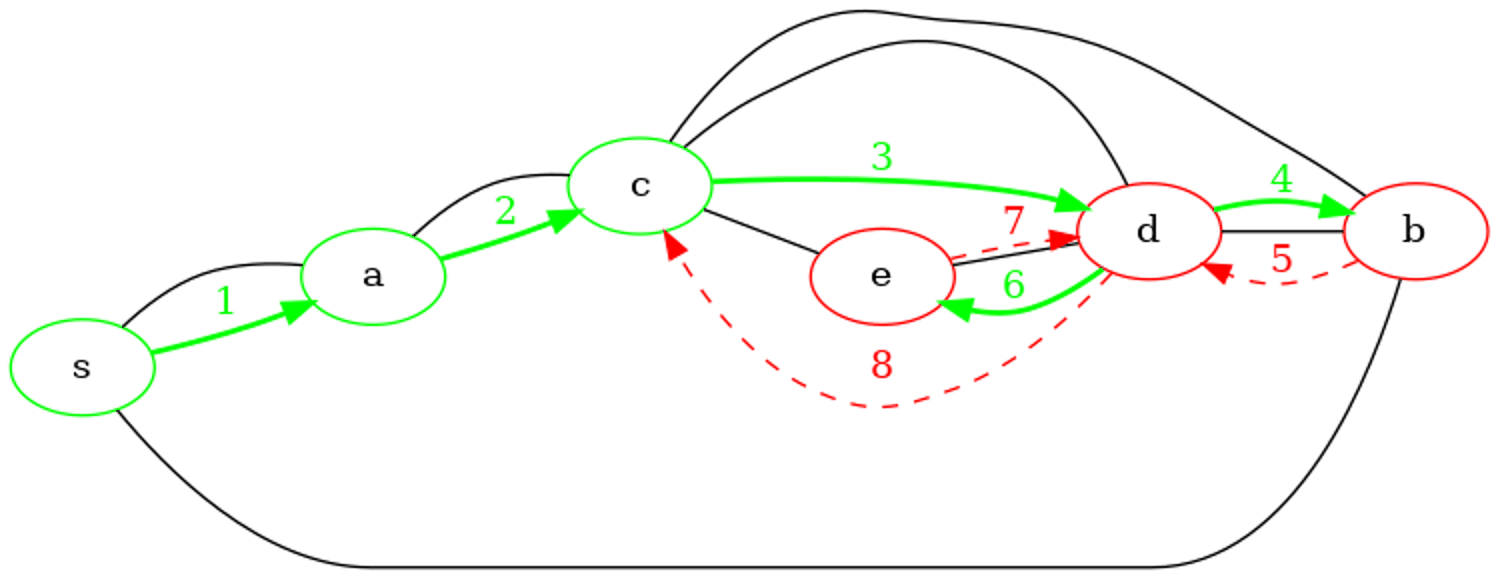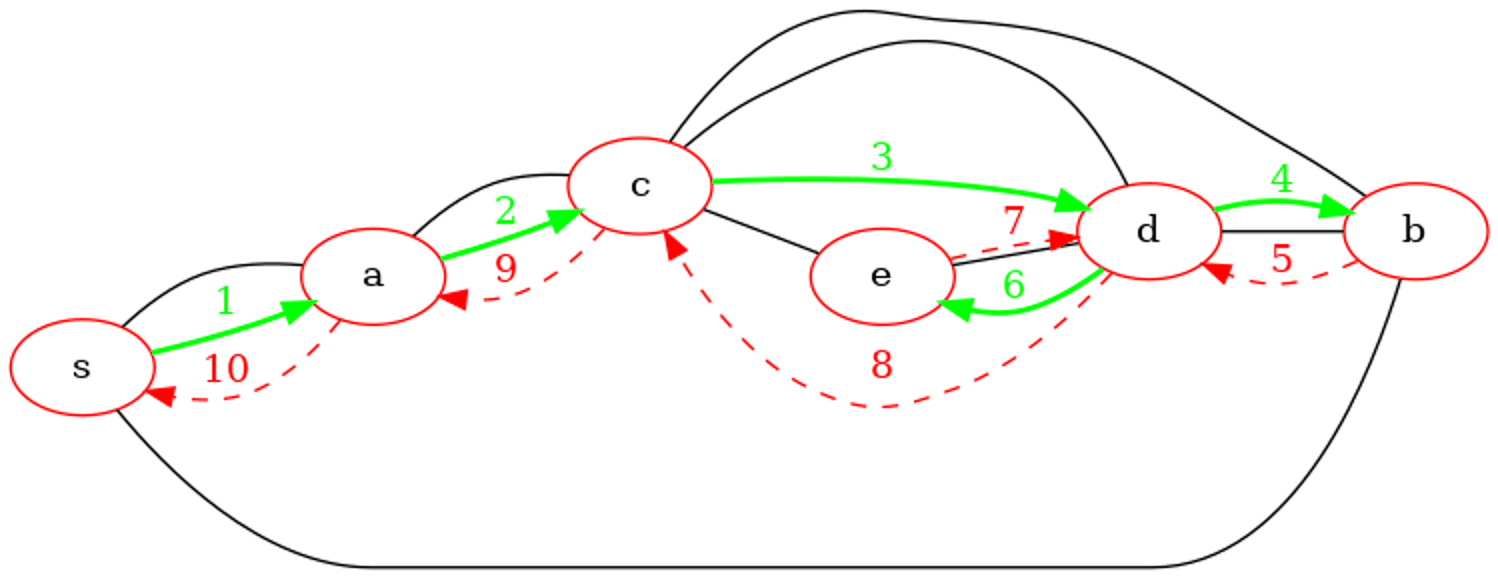
Exemple de parcours en profondeur récursif
On considère le même graphe non orienté que pour les parcours précédents avec un schéma légèrement différent.
Le graphe est représenté dans une variable g1 par un dictionnaire de listes d'adjacences comme dans l'exemple de parcours en profondeur itératif.
>>> g1.adjacents
{'s': ['a', 'b'],
'a': ['s', 'c'],
'b': ['s', 'c', 'd'],
'c': ['a', 'd', 'b', 'e'],
'e': ['c', 'd'],
'd': ['c', 'b', 'e']}
Déroulons l'appel dfs_rec('s', g1, {s: False for s in g1.sommets()}). On ne trace que les sommets dans les paramètres de la fonction. On peut remarquer que pour la même représentation par dictionnaire d'adjacences que la version itérative, l'ordre de visite des sommets à chaque profondeur est inversé. En effet, dans la version récursive, les appels récursifs sont effecutés dans l'ordre d'itération des voisins de la boucle for mais cet ordre est inversé par l'empilement sur la pile dans la version itérative.
┌Appel de dfs_rec(s) => avant
| ┌Appel de dfs_rec(a) => avant
| | ┌Appel de dfs_rec(c) => avant
| | | ┌Appel de dfs_rec(d) => avant
| | | | ┌Appel de dfs_rec(b) => avant
| | | | └Fin de dfs_rec(b) <= arrière
| | | | ┌Appel de dfs_rec(e) => avant
| | | | └Fin de dfs_rec(e) <= arrière
| | | └Fin de dfs_rec(d) <= arrière
| | └Fin de dfs_rec(c) <= arrière
| └Fin de dfs_rec(a) <= arrière
└Fin de dfs_rec(s) <= arrière
Exercice⚓︎
Exercice 14
On considère le même graphe non orienté modélisant des liaisons entre aéroports américains que dans l'exercice 13.
Ce graphe est représenté par le dictionnaire de listes d'adjacences ci-dessous :
{'JFK': ['MCO', 'ATL', 'ORD'],
'MCO': ['JFK', 'ATL', 'HOU'],
'ORD': ['DEN', 'HOU', 'DFW', 'PHX', 'JFK', 'ATL'],
'DEN': ['ORD', 'PHX', 'LAS'],
'HOU': ['ORD', 'ATL', 'DFW', 'MCO'],
'DFW': ['PHX', 'ORD', 'HOU'],
'PHX': ['DFW', 'ORD', 'DEN', 'LAX', 'LAS'],
'ATL': ['JFK', 'HOU', 'ORD', 'MCO'],
'LAX': ['PHX', 'LAS'],
'LAS': ['DEN', 'LAX', 'PHX']}
Question 1
Déterminer l'ordre de découverte de tous les sommets du graphe lors d'un parcours en profondeur récursif initié depuis le sommets étiqueté JFK.
| Sommet | Ordre de découverte |
|---|---|
| 'JFK' | 1 |
| 'MCO' | 2 |
| 'ATL' | 3 |
| 'HOU' | 4 |
| 'ORD' | 5 |
| 'DEN' | 6 |
| 'PHX' | 7 |
| 'DFW' | 8 |
| 'LAX' | 9 |
| 'LAS' | 10 |