Définitions (Bac 🎯)⚓︎

Ce cours est mis à disposition selon les termes de la Licence Creative Commons Attribution - Pas d'Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 International.

Sources et crédits pour ce cours
Pour préparer ce cours, j'ai utilisé :
- le manuel NSI chez Ellipses de Balabonski, Conchon, Filliâtre, Nguyen
- le manuel NSI chez Hachette sous la direction de Michel Beaudouin Lafon
- l'article sur les arbres en NSI de Sébastien Hoarau
- le cours de mon collègue Pierre Duclosson
- les cours de Gilles Lassus et de Franck Chambon
🔖 Synthèse de ce qu'il faut retenir pour le bac
Une structure de données dynamique⚓︎
Un problème
On veut stocker dans une structure de données des éléments tous du même type, qui sont comparables deux à deux : par exemple des nombres (notes, mesures de températures, adresses IP dans une plage d'adresses contigues ...) ou des chaînes de caractères (ISBN de livres, numéros de séries d'un parc d'ordinateurs, identifiants de clients, de produits ...).
On a deux problèmes à résoudre :
- Problème 1 : on devra effectuer fréquemment des requêtes en lecture pour rechercher un élément dans la structure ;
- Problème 2 : on devra effectuer fréquemment des requêtes en écriture pour ajouter ou enlever un élément.
Le problème 1 peut être résolu de façon efficace avec un tableau. Si on stocke \(n\) éléments et qu'on trie le tableau avec une complexité linéarithmique en \(O(n \log(n))\), on pourra effectuer chaque requête en lecture avec une complexité logarithmique en \(O(\log(n))\) en utilisant une recherche dichotomique. Mais pour insérer ou retirer un élement d'un tableau, même trié, il faudra décaler tous les éléments après ou avant, avec une complexité linéaire en \(O(n)\) dans le pire des cas ou en moyenne. Le problème 2 ne peut donc pas être résolu de façon efficace avec un tableau.
Une solution
Pour répondre aux problèmes 1 et 2, on a besoin d'une structure de données dynamique qui accepte les modifications dans des complexités acceptables : très inférieures au nombre d'éléments dans la structure si on a besoin de modifications fréquentes. Un arbre binaire de recherche est un arbre binaire vérifiant certaines propriétés qui peut autoriser ces opérations dynamiques dans des complexités de l'ordre de la hauteur de l'arbre. Si les éléments à stocker sont tous comparables, on construit un arbre binaire de recherche en répétant récursivement le traitement suivant :
- étape 1 : on choisit un noeud restant qu'on place à la racine
- étape 2 : on divise les noeuds restants en deux sous-ensembles :
- les noeuds dont l'élément est inférieur ou égal à l'élément du noeud racine vont dans le fils/sous-arbre gauche et on répète récursivement l'étape 1 dans le sous-arbre gauche
- les éléments dont l'élément est supérieur ou égal à l'élément du noeud racine vont dans le fils/sous-arbre droit et on répète récursivement l'étape 1 dans le sous-arbre droit
Lorsqu'on recherche ou insère un nouvel élément dans un arbre binaire de recherche, cette partition des noeuds permet de procéder comme pour la recherche dichotomique dans un tableau trié :
- on s'arrête à la racine
- ou on descend dans l'un des deux sous-arbres en éliminant l'autre
L'algorithme sera efficace si à chaque étape on élimine environ la moitié des éléments restants. Ce sera le cas si l'arbre est parfait ou presque complet avec une hauteur de l'ordre de \(\log_{2}(n)\).
L'ajout ou la suppression d'élément dans un arbre binaire de recherche de taille \(n\) devra donc :
- d'une part maintenir la propriété d'arbre binaire de recherche : l'ajout d'un élément, de même que sa recherche sont au programme de terminale NSI mais pas la suppression ;
- d'autre part maintenir un équilibre entre les sous-arbres pour que la hauteur de l'arbre binaire reste de l'ordre de \(\log_{2}(n)\), cette partie n'est pas au programme de terminale NSI.
Un exemple
L'IATA codé sur trois lettres permet d'identifier de façon unique un aéroport. On peut stocker dans un arbre binaire de recherche tous les codes IATA des aéroports du monde. 1 On donne ci-dessous une partie d'arbre stockant les codes de quelques aéroports. Pour chaque noeud, chaque sous-arbre représente une partition de l'espace de recherche ou d'ajout dans l'arbre d'un code IATA.
Table de données des aéroports représentés
[{'Name': 'Fort Collins Loveland Muni',
'City': 'F',
'Country': 'United States',
'IATA': 'FNL',
'ICAO': 'KFNL',
'Latitude': '40.451828',
'Longitude': '-105.011336',
'Altitude': '5016',
'Timezone': '-700',
'DST': 'A'},
{'Name': 'Heroes Del Acre',
'City': 'Cobija',
'Country': 'Bolivia',
'IATA': 'CIJ',
'ICAO': 'SLCO',
'Latitude': '-11.040436',
'Longitude': '-68.782972',
'Altitude': '892',
'Timezone': '-400',
'DST': 'U'},
{'Name': 'Melbourne Intl',
'City': 'Melbourne',
'Country': 'United States',
'IATA': 'MLB',
'ICAO': 'KMLB',
'Latitude': '28.102753',
'Longitude': '-80.645258',
'Altitude': '33',
'Timezone': '-500',
'DST': 'A'},
{'Name': 'Tambohorano Airport',
'City': 'Tambohorano',
'Country': 'Madagascar',
'IATA': 'WTA',
'ICAO': 'FMMU',
'Latitude': '-17.4761',
'Longitude': '43.9728',
'Altitude': '23',
'Timezone': '300',
'DST': 'U'},
{'Name': 'Wenzhou Yongqiang Airport',
'City': 'Wenzhou',
'Country': 'China',
'IATA': 'WNZ',
'ICAO': 'ZSWZ',
'Latitude': '27.9122',
'Longitude': '120.852',
'Altitude': '0',
'Timezone': '800',
'DST': 'U'},
{'Name': 'Westchester Co',
'City': 'White Plains',
'Country': 'United States',
'IATA': 'HPN',
'ICAO': 'KHPN',
'Latitude': '41.066959',
'Longitude': '-73.707575',
'Altitude': '439',
'Timezone': '-500',
'DST': 'A'}]
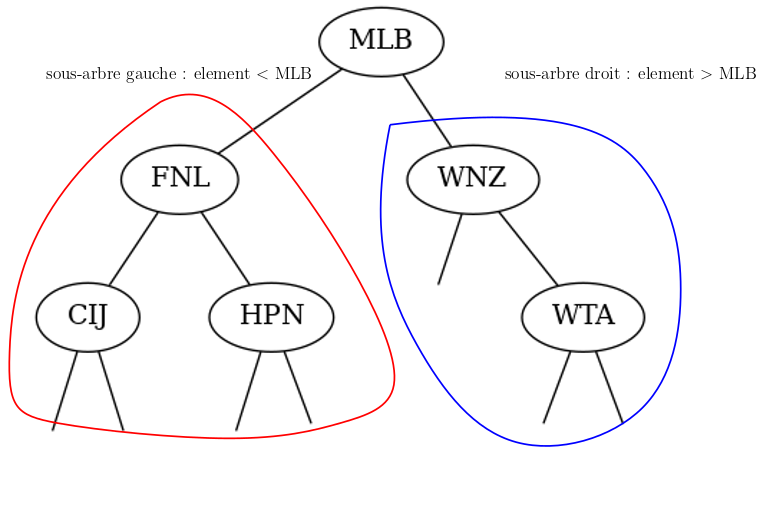
Remarque 1 : de l'arbre binaire de recherche au dictionnaire
Si on stocke dans les noeuds des couples (clef, valeur) dont la première composante est l'IATA (la clef) et l'autre une structure linéaire stockant les informations de l'aéroport, on peut obtenir une implémentation du type abstrait Dictionnaire avec des performances en lecture/écriture/suppression comparables à celle d'une table de hachage (voir TP). Les algorithmes de recherche, d'ajout ou de suppression d'élément vont comparer uniquement les clefs.
Remarque 2 : inégalités larges ou strictes ?
Pour l'arbre binaire de recherche stockant les IATA, cet identifiant d'aéroport est unique, donc il ne peut pas y avoir de doublons dans l'arbre.
Dans ce cas, on stocke un ensemble et chaque noeud racine sépare les noeuds restants selon des inégalités strictes :
- les éléments stockés dans le sous-arbre gauche sont tous strictement plus petits que l'élément racine
- les éléments stockés dans le sous-arbre droit sont tous strictement plus grands que l'élément racine
Mais si on stocke des noms de réalisateurs de films, on peut très bien avoir des doublons. Dans ce cas, on stocke un multiensemble et chaque noeud racine sépare les noeuds restants selon des inégalités larges :
- les éléments stockés dans le sous-arbre gauche sont tous inférieurs ou égaux l'élément racine
- les éléments stockés dans le sous-arbre droit sont tous supérieurs ou égaux 2 à l'élément racine
Propriété d'arbre binaire de recherche⚓︎
Point de cours 1 : propriété d'arbre binaire de recherche
Un arbre binaire de recherche (ou ABR) est un arbre binaire vérifiant certaines propriétés.
- Premier cas : un arbre binaire de recherche peut être vide
- Second cas : un arbre binaire non vide est un arbre binaire de recherche s'il vérifie les conditions suivantes :
- (C1) : tous les éléments stockés dans les noeuds sont de même type et comparables deux à deux
- (C2) : pour tous les noeuds de l'arbre binaire, l'élément stocké dans un noeud est supérieur ou égal 2 à tous les éléments stockés dans son fils/sous-arbre gauche (s'il est non vide) et inférieur ou égal 2 à tous les éléments stockés dans son fils/sous-arbre droit (s'il est non vide).
Attention
La condition (C2) doit être vérifiée pour tous les noeuds de l'arbre binaire. Il suffit donc d'un noeud ne respectant pas cette double inégalité gauche \(\leqslant\) racine \(\leqslant\) droit pour que la propriété d'ABR ne soit pas vérifiée.
Exemples
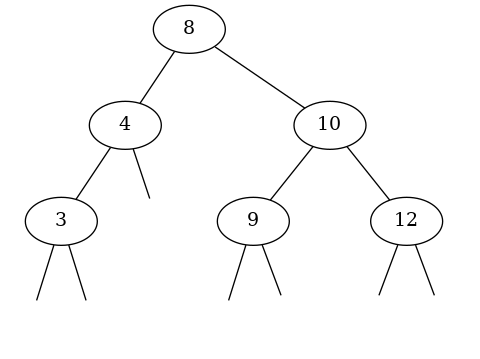
L'arbre binaire ci-dessous est non vide et vérifie la propriété d'arbre binaire de recherche :
- tous les éléments sont des entiers comparables deux à deux ;
- pour tous les noeuds, l'élément stocké dans le noeud est supérieur à tous les éléments stockés dans son sous-arbre gauche et inférieur à tous les éléments stockés dans son sous-arbre droit
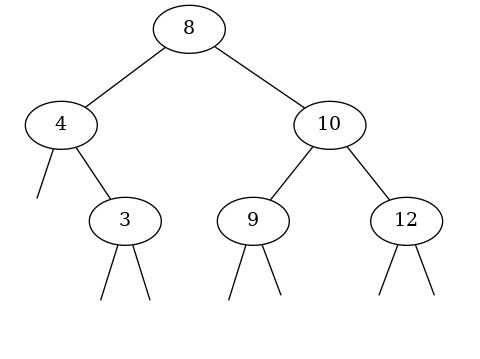
L'arbre binaire ci-dessous est non vide et contient des éléments entiers comparables deux à deux, mais il ne vérifie pas la propriété d'arbre binaire de recherche :
- l'élément 4 n'est pas inférieur ou égal à l'élément 3 qui se trouve dans le sous-arbre droit du noeud où il est stocké.
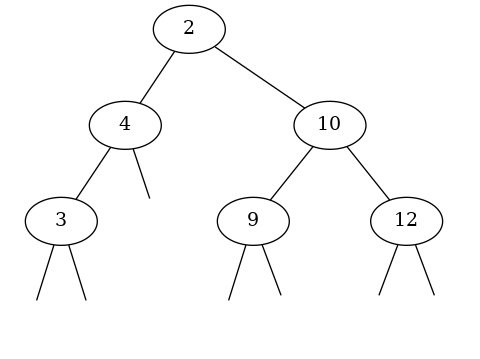
L'arbre binaire ci-dessous est non vide et contient des éléments entiers comparables deux à deux, mais il ne vérifie pas la propriété d'arbre binaire de recherche :
- l'élément 2 n'est pas supérieur ou égal aux éléments 3 et 4 qui se trouvent dans le sous-arbre gauche du noeud où il est stocké.
Exercice 1
L'arbre binaire de recherche ci-dessous contient des codes IATA (trois caractères majuscules entre 'A' et ̀'Z').
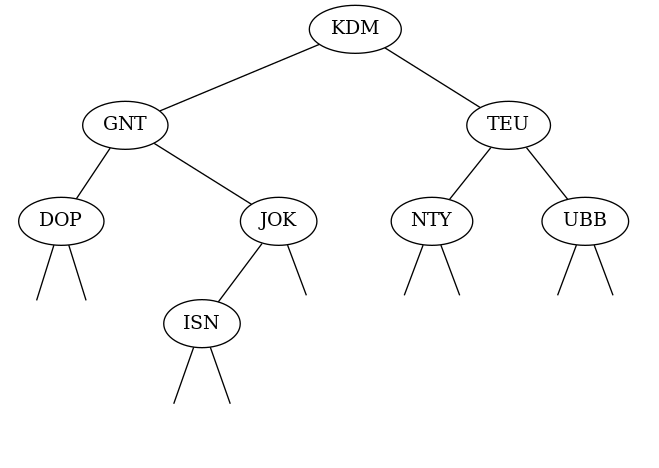
Question 1
Donnez un élément qu'on peut insérer dans le noeud fils droit du noeud contenant 'DOP'.
'DOQ' car 'DOP'<'DOQ'.
Question 2
Donnez un élément qu'on peut insérer dans le noeud fils gauche du noeud contenant 'NTY'.
'NTX car 'NTX'<'NTY'.
Question 3
On veut insérer l'élément 'NSI' comme feuille de l'arbre, où peut-on le placer pour que la propriété d'arbre binaire de recherche soit conservée. Décrivez un algorithme pour trouver sa place.
Comme fils droit de 'NTX'. On descend dans l'arbre depuis la racine x : dans le sous-arbre gauche si 'NSI' est inférieur à l'élément stocké dans le racine ou dans le sous-arbre droit s'il est supérieur. On s'arrête quand le sous-arbre où l'on doit descendre est vide, on y insère un noeud avec l'élément 'NSI'.
Question 4
Comment caractériser le noeud qui contient le plus petit élément stocké dans cet arbre binaire de recherche ?
Le plus petit élément se trouve dans le noeud atteint lorsqu'on descend toujours dans le sous-arbre gauche depuis la racine jusqu'à ce que le sous-arbre gauche soit vide. Ici il s'agit de 'DOP'
Question 5
Comment caractériser le noeud qui contient le plus grand élément stocké dans cet arbre binaire de recherche ?
Le plus grand élément se trouve dans le noeud atteint lorsqu'on descend toujours dans le sous-arbre droit depuis la racine jusqu'à ce que le sous-arbre droit soit vide. Ici il s'agit de 'UBB'
Question 6
Enumérez les éléments stockés dans cet arbre en le parcourant dans l'ordre infixe. Que remarque-t-on ?
On obtient 'DOP', 'GNT', 'ISN', 'JOK', 'KDM', 'NTY', 'TEU', 'UBB' qui est la séquence des éléments triée dans l'ordre croissant.
-
Avec \(26^{3}\) codes IATA possibles et des ajouts/suppression beaucoup moins fréquents que les recherches, l'avantage d'un arbre binaire de recherche par rapport à un tableau trié est discutable. La différence devient critique dès que les ajouts/suppressions sont plus fréquents comme dans le stock d'une grosse plateforme logistique par exemple. ↩
-
L'inégalité peut devenir stricte si on veut exclure les doublons pour stocker un ensemble. ↩↩↩